Neues aus dem Open Password Archiv
15.04.2024 – Genios Datenbanken aufgrund von Hacker Angriff weiterhinnicht erreichbar. Wir prüfen täglich die Verfügbarkeit und haben aktuelle Informationen zum Ausfall des Datenbankhosts hier.
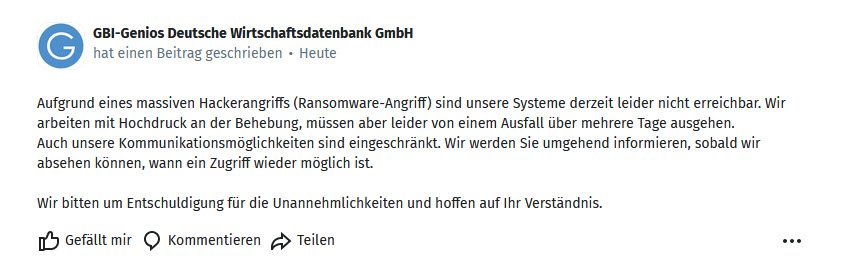
Weitere Informationen und Links zum Genios Ausfall in einem Beitrag mit aktuellem Status.
Open Password Archiv – GPT – Gigantische Möglichkeiten
Stellen Sie sich einfach vor, alle Open Password Beiträge (1109 Artikel) werden mittels einer KI auswertbar und durchsuchbar. Beiträge recherchieren, Experten und deren Meinung lokalisieren. Fakten zusammenfassen. Dies sind nur einige Funktionen, die das neue Open Password Archiv in der Kopplung mit ChatGPT bietet. Was wäre, wenn sich komplette Aufsätze mit dieser Funktion schreiben lassen? Nicht nur in deutscher, sondern beispielsweise in französischer Sprache. Klingt verrückt und ist dennoch möglich.
Ab sofort stehen alle Open Password Beiträge von 2016 bis 2022 im Volltext per ChatGPT als eigener GPT zur Verfügung. Kostenfrei für alle ChatGPT Plus Nutzer.
Meistgelesen in der letzten Woche (15.KW 2024)
OPEN PASSWORD ARCHIV

KÜNSTLICHE INTELLIGENZ
KI in der Datenanalyse


DIGITALISIERUNG
Chance oder Risiko?
Open Password Archiv – Beitragsübersichten
30. Juni 2022 A Farewell to a Writer: Willi Bredemeier – Kollege – Partner – Freund – Von Elisabeth Simon
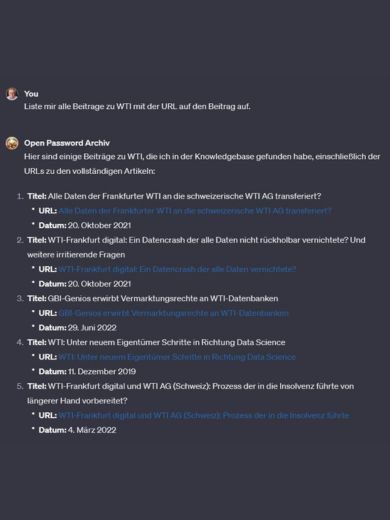
29. Juni 2022 GBI-Genios erwirbt Vermarktungrechte an WTI-Datenbanken
28. Juni 2022 Global Standards Publishing – Segment View 2022. Part III
27. Juni 2022 WTI-Frankfurt digital und FIZ Technik: Der Niedergang begann mit FIZ Technik
24. Juni 2022 Global Standards Publishing – Segment View 2022. Part II
23. Juni 2022 Steilvorlagen 2022: Richtige Informationen, falsche Schlüsse – Die Crux mit der Fehleinschätzung
22. Juni 2022 Global Standards Publishing – Segment View 2022
20. Juni 2022 Wissenschaftliche Revolutionen: Auf dem Weg zu neuen Basistheorien in der Physik
17. Juni 2022 Die Bibliothek der Dinge in Bochum
15. Juni 2022 ASpB: Die Perspektiven für die kommenden Jahre
14. Juni 2022 Spuren deutschsprachiger Wissenschaftler in der Jemen-Forschung
13. Juni 2022 Wissensgraphen, Linked Open Data und Ontologien für die Datenbestände des ZPID
10. Juni 2022 Julia Kohlbach liest das Buch ihres Lebens: „Ein ganzes halbes Jahr“ von Jojo Moyes
8. Juni 2022 75 Jahre ASpB: Der Spirit und Zusammenhalt der ersten Jahre sind immer noch da (II)
7. Juni 2022 Kartons im Keller – was tun mit ungeöffneten Nachlässen?
3. Juni 2022 Russland-Ukraine-Konflikt: Wie die Medien über den Krieg berichten
1. Juni 2022 ASpB: 75 Jahre wechselnde Herausforderungen bestanden und der Spirit und Zusammenhalt der ersten Jahre sind immer noch da
31. Mai 2022 „Open Password Archiv Plus“ wird unter infobroker.de weitergeführt
30. Mai 2022 Weißbuch „Citizen-Science-Strategie 2030 für Deutschland“ – ein partizipativer Prozess
27. Mai 2022 The Syllabus: Eine Alternative zu Google und den Sozialen Medien?
25. Mai 2022 Security-Prognosen Datenschutz, Digitale Kommunikation, Embedded Software und Deep Fakes
24. Mai 2022 Stephan Holländer wird Ehrenmitglied von Bibliosuisse – Von Sabine Graumann
23. Mai 2022 Forschungsdatenmanagement: Neuer Ansatz mit „Pandemie-Push“ in Bibliotheken
20. Mai 2022 Katharina Loonus liest das Buch ihres Lebens: „Siddharta“ von Hermann Hesse
18. Mai 2022: Stärkung der gesellschaftlichen Resilienz durch Bibliotheken und Geisteswissenschaften
17. Mai 2022: Bibliotheken. Wegweiser in die Zukunft. Projekte und Beispiele: Jetzt auch als Open Access in der Universitätsbibliothek der RUB
16. Mai 2022 Erschließung aus Nutzersicht: Ein neuer Online-Katalog für das Deutsche Literaturarchiv Marbach
11. Mai 2022 Awareness-Mentalität und strategisches Verhalten in der Wissenschaft: Die Forschung auf dem Wege von „Being Good“ zu „Looking Good“? (II)
10. Mai 2022 60 Jahre Universitätsbibliothek der Ruhr-Universität Bochum: „Exzellente Universitäten haben exzellente Bibliotheken“
9. Mai 2022 Wolters Kluwer to Roll ESG Considerations into Financial Reporting
6. Mai 2022 Christina Marinidis liest das Buch ihres Lebens: „Erec“ von Hartmann von Aue
4. Mai 2022 Öffentliche Bibliotheken und die Pandemie: Zeit der Experimente, der neuen digitalen Dienste und der Mühen, Kunden nahe zu sein
3. Mai 2022 Wissenschaftliche Revolutionen Auf dem Weg zu neuen Basistheorien in der Physik Oder sind die Messungen nur ungenau?
2. Mai 2022 Awareness-Mentalität und strategisches Verhalten in der Wissenschaft: Die Forschung auf dem Wege von „Being Good“ zu „Looking Good“?
29. April 2022 Elisabeth Simon liest das Buch ihres Lebens: „Dr. Faustus“ von Thomas Mann
27. April 2022 Gamification auf Social Live Streaming-Diensten
26. April 2022 Prof. Dr. Hans-Jürgen Manecke: Sagen, was ist: Wie die Informationsinfrastruktur in den Neuen Bundesländern unterging
25. April 2022 F.A.Z.-Archiv: Werkstattbericht „Archivierung und Vermarktung von Audiodaten“, II. Teil
22. April 2022 Vivian Stroetmann liest das Buch ihres Lebens und entdeckt existenzielle Fragen, die nicht zu beantworten sind
20. April 2022 F.A.Z.-Archiv: Werkstattbericht „Archivierung und Vermarktung von Audiodaten
13. April 2022 Marc Berenbeck: Mit „Ready to Use“-Analysen und Ausarbeitungen als Grundlage für strategische Entscheidungen in Kundenunternehmen
11. April 2022 The Information Industry is Largely Bouncing Back – Concerns Over Inflation and Russia´s Invasion of Ukraine
8. April 2022 Dr Zhivago: Ein Buch setzt sich weltweit gegen den KGB und die Regierung der Sowjetuinon durch
6. April 2022 Steilvorlagen 2021: Die Kunst der Entscheidung – Gut informieren oder besser beraten?
4. April 2022 Open Science Conference 2022: Datentracking, Regulierung von „Text und Data Mining“, Open Science und Ungleichheit
1. April 2022 The Zivago Affair: The Kremlin, the CIA and the Battle over a Forbidden Book
30. März 2022 Angriffskrieg gegen die Ukraine: Wie kommunizieren wir mit dem Feind und wie positionieren wir uns zu ihm?
28. März 2022 Eine moralische Revolution in den Köpfen der CEOs und der Finanziers der Tech-Branche geboten
25. März 2022 Jochen Lennhof liest das Buch seines Lebens. „Jim Knopf und der Lokomotivführer“ von Michael Ende
23. März 2022 Nutzung digitaler Medien und Informations- und Kommunikationstechnologien von Asylbewerbern
21. März 2022 Global Library Information Market: Forecast and Trends (Part II)
18. März 2022 Barbara Schulz-Bredemeier macht aus Harry Potter ein Drei-Generationen-Familienprojekt
16. März 2022 Die Kollateralschäden von Silicon Valley: Ausbeutung von Ländern, Regionen und Arbeitnehmern
14. März 2022 IDESA: The Role of Information Professionals for Civic Development in Bosnia and Herzegovina
11. März 2022 Roland Jerzewski liest das Buch seines Lebens: „…diese Stunde, die wie ein Pfeil im Herzen des Tages zittert“
9. März 2022 Global Library Information Market: Forecast and Trends
7. März 2022 Wirtschaftsjournalisten und InfoPros: Gemeinsame Schnittmengen und Ergänzungen
4. März 2022 WTI-Frankfurt digital und WTI AG (Schweiz): Prozess, der in die Insolvenz führte, von längerer Hand vorbereitet?
2. März 2022 44. Kolloquium TU Ilmenau: Internatiionalisierung und Digitalisierung der IP-Welt
28. Februar 2022 New and elaborate ideas in the exponentially growing field of Data Analytics
25. Februar 2022 Bücher, die uns bewegten: Jeder Mensch ist ein Künstler! Jeder Künstler ist ein Mensch!
23. Februar 2022 George Orwell nur in Teilen der Welt in den Griff bekommen – Huxleys „Brave New World“ ist weltweite Wirklichkeit
21. Februar 2022 Wissenschaftliche Bibliotheken und die Pandemie: Corona als der große Beschleuniger, Innovationstreiber und Bewirker dezentraler Kollaboration
16. Februar 2022 Eine Plattform für die Wirtschaft von morgen – Die Entwicklung redaktioneller Popstars
14. Februar 2022 Patent Research Solutions Survey 2022: Customer Needs
11. Februar 2022 Frau des Jahres 2022/2021 Frances Haugen: Mit Materialbergen und klarem moralischen Kompass das illegitime Handeln von Facebook aufgedeckt
9. Februar 2022 Martine Demay liest das Buch ihres Lebens: „Trobadora Beatriz“ von Irmtraud Morgner
7. Februar 2022 ASpB-Tagung: „Im Dickicht der Einzelheiten“: Herausforderungen und Lösungen für die Erschließung
4. Februar 2022 Virtuelle Bildungsmesse: Eine “Didacta” en miniature und ein Plädoyer für fachliche Fortbildung
2. Februar 2022 Hommage an das Buch: Mit Herzblut, Leidenschaft und tiefen Kenntnissen geschrieben
31. Januar 2022 Erfahrungsbericht AI-SDV 2021: An den Fronten der Suche, Datenanalyse, Visualisierung und Wissensverarbeitung (II)
28. Januar 2022 36 Jahre die Entwicklung der Branche mit Hilfe prägender Trends interpretiert
26. Januar 2022 Ein Sommerleseclub für alle Bibliotheken in Nordrhein-Westfalen
24. Januar 2022 Wie die Redaktion des Handelsblatt heute arbeitet
21. Januar 2022 AI-SDV: An den Fronten der Suche, Datenanalyse, Visualisierung und Wissensverarbeitung
19. Januar 2022 IT-Prognosen 2022: Security, Internet of Things,
17. Januar 2022 Bibliotheken als Demokratisierer des Wissens, Diskursraum für strittige Meinungen und digitaler dritter Ort
14. Januar 2022 After Corona: Cleenup will Take Many Years and May Require a New Approach
12. Januar 2022 Trend des Jahres: Corona als der große Beschleuniger
11. Januar 2018 : Market and Competitive Intelligence für Schmierstoffe und Krebsdiagnostik
10. Januar 2022 Industrielle Verbreitung von Fake News, die global Demokratien bedroht
20. Dezember 2021 Mit abgelederter Arbeitstasche und Schweiß auf der Stirn stets schönes Story Telling
17. Dezember 2021 Teilnehmer bewerten „Steilvorlagen“ nach Schulnoten mit 1,8 – 95% würden Veranstaltung weiterempfehlen
15. Dezember 2021 Warum es mich bei „Open“ und „Passwort“ schaudert und ich „Open Password“ zugetan bin
13. Dezember 2021 UK in the Post-Brexit Age: Copyright Law Reforms on the Horizon
10. Dezember 2021 Gamification auf Social-Live-Streaming-Diensten
9. Dezember 2021 Streiflichter, wie die InfoPros ticken
6. Dezember 2021 Der h-Index – „ein nutzloser bibliometrischer Index“
3. Dezember 2021 Unermüdliche Wahrnehmung einer Informationsfilter- und Wächterfunktion
1. Dezember 2021 FAIR Data Austria und Forschungsdatenmanagement in Österreich
30. November 2021 Corona-Pandemie: Vor der allgemeinen Impfpflicht und dem dritten Lockdown
26. November 2021 Zu groß der Tatendrang, zu spitz die Feder: Zur 1000. Ausgabe von Open Password
24. November 2021 cOAlition S and UKRI Say Scholarly Books Must be Open Access
22. November 2021 Trends im KYC-Markt – KYC-Prüfung in digitalen Workflow-Schritten vereinfachen
19. November 2021 Die 1000. Ausgabe von Open Password
17. November 2021 Minesoft: Trotz Brexit und Corona erfreulich über die Runden gekommen
15. November 2021 Informationskompetenz kann immer nur vorläufig sein
12. November 2021 Opening Up Science – KLARtexte als Tor zur Wissenschaft
10. November 2021 ZoomInfo: A New Strong European Information Provider
8. November 2021 13. Wildauer Bibliothekssymposium: Bibliotheken als virtuelle und reale Räume
5. November 2021 Die Entdeckung des Möglichen: ZB MED in Zeiten der COVID-19-Pandemie
3. November 2021 What does Popper`s “Es gibt keine Autoritäten” mean? – Eine Antwort auf Herbert Huemer und Bernd Jörs
29. Oktober 2021 Startup Cassyni Targeting Research Seminars
27. Oktober 2021 Stadtbibliothek Paderborn ist Bibliothek des Jahres
25. Oktober 2021 Open Access-Tage: Echte Partizipation statt bloße Zugeständnisse
22. Oktober 2021 Alle Daten der Frankfurter WTI an die schweizerische WTI AG transferiert?
20. Oktober 2021 WTI-Frankfurt digital: Ein Datencrash, der alle Daten nicht rückholbar vernichtete? Und weitere irritierende Fragen
18. Oktober 2021 Steilvorlagen 2021: Mit Echtzeit-News und Data-Analytics die Performance der Unternehmen verbessern
15. Oktober 2021 Erfolgsbedingungen strategischer Veränderungen in Spezialbibliotheken
13. Oktober 2021 Convergence Monitor 2021: Die Trends bei Audio- und Videodiensten
11. Oktober 2021 Wissenschaftliche Spezialbibliotheken: Wohin geht die Reise?
8. Oktober 2021 vfm: Trotz Schließung von Dokumentationsstellen leichter Anstieg der Mitgliederzahlen
6. Oktober 2021 Planet Erde: Tipping Points identifizieren, in die Ferne verschieben
4. Oktober 2021 Zwischen notwendiger Informationssuche und Informationsmeidung durch Überlastung
1. Oktober 2021 The Biggest Trends in Cybersecurity
29. September 2021 Das große Versäumnis der Bibliotheks- und Informationswissenschaft im Zeitalter der Desinformation
27. September 2021 Back to Basics: Exploring the Identity of the Information Professional
24. September 2021 Ibbenbüren: Stadtbibliothek und Schulen Hand in Hand für Medien- und Informationskompetenz
22. September 2021 Die Mehrheit der Jugendlichen achtet beim Shoppen auf Nachhaltigkeit
20. September 2021 An Bibliotheken und mit Bibliotheken im Weißbuch „Citizen Science-Strategie 2030 für Deutschland“
17. September 2021 Start of „Salesforce+ as „Business Netflix“
15. September 2021 Trend zur nicht-linearen Nutzung und zu mehr Zeitsouveränität setzt sich fort
14. September 2021 Information Professionals haben eine Zukunft, sie sind sogar unverzichtbar. Aber wie stellen sie das an?
10. September 2021 Stadtbibliothek Ibbenbüren und Schulen Hand in Hand für Medien- und Informationskompetenz
8. September 2021 Wie erst spezifisches Fachwissen zu Medien- und Informationskompetenz führen kann
6. September 2021 Die APA im Jubiläumsjahr: Corona als „Durchstartknopf für Digitalisierung“
3. September 2021 Steilvorlagen 2021: Die Inhalte
1. September 2021 Jugend-Digitalstudie 2021: WhatsApp, YouTube und Instagram am wichtigsten, aber TikTok holt auf
30. August 2021 Gegen die Selbstüberschätzung der Vertreter der „Informationskompetenz“ eine Rückkehr zu Karl. R. Popper geboten
27. August 2021 Credit Information in a Post Pandemic Digital World
25. August 2021 Mehr Teilnahme, Transparenz und Gemeinschaft durch Libraries, Archives, Museums
23. August 2021 Steilvorlagen 2021: Die Kunst der Entscheidung
20. August 2021 Wie sich „Informationskompetenz“ methodisch-operativ untersuchen lässt
18. August 2021 How Experian is Building a Sustainable Future Worldwide
16. August 2021 Stadt- und Kreisbibliothek „Anna Seghers“ Meiningen: Überall präsent, wo die Nutzer unterwegs sind
13. August 2021 Das große Missverständnis und Versäumnis der Bibliotheks- und Informationswissenschaft im Zeitalter der Desinformation
11. August 2021 A New Breed of Governement, Risk and Compliance Solutions Evolves from Alternative Data
9. August 2021 Bibliotheken. Wegweiser in die Zukunft Projekte und Beispiele Die HerausgeberInnen. Die Autoren
6. August 2021 Gaming: Bibliotheksferne Gruppen heranführen
4. August 2021 Activity Tracking für Fitness, Forschung und Litearcy
2. August 2021 Beck-Verlag benennt drei rechtliche Standardwerke nicht mehr nach Nazi-Größen
30. Juli 2021 Ein aufwendiger, aber erfolgreicher Weg zum „Dritten Ort“ II
28. Juli 2021 Technologischer Wettlauf zwischen USA und China: Gigantische Hoffnungen, Milliardeninvestitionen, doch der pragmatische Durchbruch des Quantencomputers steht aus
26. Juli 2021 Wie digital wollen wir leben? Die Rezension
23. Juli 2021 Stadtbücherei Olsberg: Ein aufwendiger, aber erfolgreicher Weg zum „Dritten Ort“
21. Juli 2021 Lernmaterialien für junge Forschende in den Wirtschaftswissenschaften als Open Educational Resources III
19. Juli 2021 ISI 2021: Ein kleines Fach zwischen „Daten“ und „Wissen“ II
16. Juli 2021 Zur gesellschaftlichen Verantwortung der Informationswissenschaften
14. Juli 2021 Fernsehen 3.0: Automatisierte Sentimentanalyse und Zusammenstellung von Kurzvideos mit hohem Aufregungslevel
12. Juli 2021 ISI 2021: Ein kleines Fach zwischen „Daten“ und „Wissen“
9. Juli 2021 Frankfurt Book Fair: Re:connect: Renewed Impetus für Success
7. Juli 2021 Bibliotheken sollten nicht nur Wegweiser in die Zukunft sein. Sie sind es.
5. Juli 2021 The Multiple Paths of a Blackstone-Infused IDG
2. Juli 2021 EconBiz Academic Career Kit: Didaktisches Konzept – Bereitstellung interaktiver Lerninhalte – CC-Lizenzen in der Praxis
30. Juni 2021 Quantencomputer: Gigantische Hoffnungen, Milliardeninvestitionen, doch der pragmatische Durchbruch des Quantencomputers steht aus
28. Juni 2021 Klassifikation für interdisziplinäre Forschungsfelder veröffentlicht
25. Juni 2021 Informationskompetenz muss vor allem aus einem kompetenten Umgang mit Google bestehen
23. Juni 2021 Work-Life-Balance im Home Office: Besser oder anstrengender?
21. Juni 2021 Neu erschienen: Bibliotheken. Wegweiser in die Zukunft. Projekte und Beispiele
18. Juni 2021 Anprangerung fehlender Gendergerechtigkeit mit der eigenen Forderung nach Altersdiskriminierung verrechnet
16. Juni 2021 Lernmaterialien für junge Forschende in den Wirtschaftswissenschaften als Open Educational Resources (OER)
14. Juni 2021 Key Demandbase Acquisitions Power New Modular Cloud Offering
11. Juni 2021 Eagle Alpha: Connecting the Universe of Alternative Data
9. Juni 2021 Agiles Arbeiten bei RTL news und SWR
7. Juni 2021 Bibliothek trifft Journalismus: „Into Therapy“
4. Juni 2021 How Innovative Corporate Use External Data to Enhance Decision Making (III)
2. Juni 2021 IDESA 2020 Sarajewo: Information Literacy and its Role for Democarcy
31. Mai 2021 Koordinierung auf der Basis eines gemeinsamen Metadatenformates in den deutschen und österreichischen Bibliotheksverbünden
28. Mai 2021 Social Media Atlas 2021: Deutliche Nutzungsunterschiede nach Bundesländern
26. Mai 2021 Legal Tech Providers Rocket Lawyer and Clio Fuel up to Take on the Same Market
21. Mai 2021 Case Studies: Wissenrepräsentation durch RDF
19. Mai 2021 Case Studies: How Innovative Corporate Use External Data to Enhance Decision Making
17. Mai 2021 Roboter Writing Investment Reports
14. Mai 2021 Mehrwert und Implementierung von Wissensgraphen
12. Mai 2021 Schafft die Digitalisierung die Journalisten ab?
10. Mai 2021 Ein Metadatenformat für Bestandserhaltung und Archivierung
7. Mai 2021 Zukunft der Informationswissenschaft: Wie bringen wir Geschichte und aktuelle Praxis zusammen?
5. Mai 2021 Ranking Sozialer Medien in Deutschland – PATINFO kehrt zur Virtualität zurück
3. Mai 2021 Open-Bildungsdaten-Portale vor allem lokal verbesserungsfähig
30. April 2021 „Praxishandbuch Forschungsdatenmanagement“ ein sehr guter Ratgeber
28. April 2021 Bibliotheken vor neuen Abhängigkeiten von der Publishing-Industrie
26. April 2021 Grenzen der Bildähnlichkeitssuche
23. April 2021 How Innovative Corporate Use External Data to Enhance Decision Making
21. April 2021 Die Influencer auf dreistelligen Informationsmärkten
19. April 2021 Ineternet-Nutzung nimmt unter Corona-Bedingungen stark zu
16. April 2021 Vom richtigen Umgang mit Texten und Sozialen Medien
14. April 2021 Virtual Event Best Practices
12. April 2021 Maschinelles Lernen: Extraktion visueller Merkmale
9. April 2021 ZB MED vor Verschmelzung mit BIBI – Die Strategie bis 2025
7. April 2021 Nach welchen Sternen sollen Bibliotheken greifen?
31. März 2021 Hans-Christoph Hobohm, ich und die Jahrzehnte, in denen wir für die Bibliotheken lebten
29. März 2021 What is Information Literacy and how to improve it?
26. März 2021 Geld, Aufmerksamkeit, die eigenen Daten und Fan-Loyalität als Währungen
24. März 2021 Focus on Value: Challenging Traditional Views of Industry Definitions
22. März 2021 Vom Glück und der Ereignislosigkeit in der Bibliothek
19. März 2021 Herausforderungen, Lösungen und Grenzen der Bildähnlichkeitssuche
17. März 2021 Was aus der Informationswissenschaft geworden ist
15. März 2021 The „Library of International Standards“
12. März 2021 ISI 2021: Die Verbesserungsmöglichkeiten
9. März 2021 Mit PATINFO im Juni wieder Präsenzveranstaltungen
8. März 2021 Interne Schwarmintelligenz mit smarter Lösung nutzbar machen (II)
5. März 2021 Call for Papers: „Das Buch, das mein Leben veränderte“
3. März 2021 Open Science is here to stay – Die Open Science Conference
2. März 2021 Die Pandemie trifft vor allem die Armen und Bildungswilligen
26. Februar 2021 Open Science is here to stay
25. Februar 2021 HI und deutsche Informationswissenschaft vor neuem Start
24. Februar 2021 Best-Practice-Programm für den Originalerhalt schriftlichen Kulturguts (II)
22. Februar 2021 Talent, Transformation and Trust as Decisive Success Factors
19. Februar 2021 Externe Expertennetzwerke: Die Perspektive der Kunden
17. Februar 2021 Länder- und spartenübergreifendes Best-Practice-Programm für den Originalerhalt schriftlichen Kulturguts
15. Februar 2021 Wie bei der Überführung eines Bildarchivs letzten Endes alles gut ausgeht
12. Februar 2021 Externe Expertennetzwerke für InfoPros unverzichtbar
10. Februar 2021 Biberach: Lesenester und Kindergartenbüchereien
8. Februar 2021 Ist der Durchbruch wissenschaftlichen Wissens wirklich irreversibel?
5. Februar 2021 2020-1986: Trends, Männer und Frauen, die unsere Branche bewegten
3. Februar 2021 InfoPros: Vor der Gestaltung innovativer Umfragen und der proaktiven Vorbereitung strategischer Entscheidungen?
1. Februar 2021 Ausbreitung und Vervollständigung wissenschaftlichen Denkens
29. Januar 2021 6 Trends für digitale Kundenkommunikation
27. Januar 2021 Alternative Data vs. Alternative Facts – Die Trade Offs
26. Januar 2021 Stärkung der digitalen Souveränität der Schüler
25. Januar 2021 Entfaltung und Degeneration des Social Web
22. Januar 2021 Bibliotheken gegen Fake News als Mission
20. Januar 2021 Sollten wir öffentlich-rechtliche Soziale Medien einführen? Möglicherweise
18. Januar 2021 2020 Events and What They Mean for 2021
15. Januar 2021 Nur mit Impfpflicht werden wir der Pandemie Herr
13. Januar 2021 Zeitschriftenmonitoring im Forschungszentrum Jülich: Die Ergebnisse
11. Januar 2021 „Digital or Die“ Time for Companies
8. Januar 2021 Zoom: Unternehmen des Jahres 2020
6. Januar 2021 Steilvorlagen: Wie es 2021 weitergehen soll
4. Januar 2021 Das Jülicher Modell zum Zeitschriftenmonitoring
18. Dezember 2020 Trend des Jahres: COVID-19 – Leben in der Semi-Quarantäne
16. Dezember 2020 COVID-19: Erkrankung und Gesundung eines InfoPros
14. Dezember 2020 Steilvorlagen 2020: Noch höhere Zustimmung als 2019
11. Dezember 2020 Elektronische Laborbücher als Teil des Forschungsdatenmanagements
9. Dezember 2020 CEO Outlook for 2021: Returning to Pre-Pandemic Levels 2022 or Later
7. Dezember 2020 Die existenziellen Probleme der Menschheit durch Öffentlichkeitsarbeit lösen?
4. Dezember 2020 Qurator: Kuratierung digitalisierter Dokumente mit Künstlicher Intelligenz (IV)
2. Dezember 2020 SVP: Seit 40 Jahren auf der Datenautobahn
30. November 2020 Wege aus einer selbstverschuldeten Krise der Informationswissenschaft
27. November 2020 Wie „Know Your Customer“ organisiert werden kann
25. November 2020 Qurator: Kuratierung digitalisierter Dokumente mit Künstlicher Intelligenz (III)
23. November 2020 Eine ZBW-Strategie bis 2025
20. November 2020 Qurator: Kuratierung digitalisierter Dokumente mit Künstlicher Intelligenz (II)
18. November 2020 Mehr Drama und Drive durch Echtzeit-Umfragen
16. November 2020 Springer and MPDL Agree on OA Terms for the Nature Portfolio
13. November 2020 Qurator: Kuratierung digitalisierter Dokumente mit Künstlicher Intelligenz
11. November 2020 Scheitert erweiterte Risikoethik für Kernenergie und Klimawandel an ihren Stakeholdern?
9. November 2020 30 Jahre Übernahme der Neuen Bundesländer durch die Bundesrepublik Deutschland
6. November 2020 Best Practice in einer wissenschaftlichen Spezialbibliothek (III)
4. November 2020 Inwieweit und warum die „Steilvorlagen 2020“ auch im neuen Format ein Erfolg wurden
2. November 2020 Zum Transfer der wissenskulturellen Perspektive – Teil 2
30. Oktober 2020 Zum Transfer der wissenskulturellen Perspektive in die bibliothekarische Praxis
28. Oktober 2020 Informationsdidaktik für verschiedene Wissenskulturen
26. Oktober 2020 Best Practice in einer wissenschaftlichen Spezialbibliothek (II)
22. Oktober 2020 Best Practice in einer wissenschaftlichen Spezialbibliothek
21. Oktober 2020 10 Empfehlungen für den Einsatz von KI zur Verbesserung von Datenschutz und Datensicherheit
19. Oktober 2020 Dun & Bradstreet Acquires Bisnode: The Analysis
15. Oktober 2020 Community-Led B2B Business Model Extension
14. Oktober 2020 Springer Nature´s successful collaboration with ResearchGate
12. Oktober 2020 94 Prozent der Deutschen nutzen das Internet
9. Oktober 2020 ZB MED: Services für den kompletten Forschungskreislauf
7. Oktober 2020 Vor unbeherrschbaren Risiken? In einer spirituellen Krise
5. Oktober 2020 Ressourcen, Strategien und Perspektiven von Citizen Science
2. Oktober 2020 Bürgerwissenschaftler auf Augenhöhe mit etablierter Wissenschaft
1. Oktober 2020 Die Frankfurter Buchmesse für Publishing Professionals
29. September 2020 Nutzer spielen lassen und wertvolle Daten gewinnen
28. September 2020 Hommage, die den Enthusiasmus der Pionierbranche wiederaufleben lässt
25. September 2020 Persönliche Verantwortung im Zeitalter der Verschleuderung der Ressourcen unseres Planeten
24. September 2020 Nach Bombenfund, Evakuierung und Corona-Pandemie eine gelungene Virtualisierung
22. September 2020 Epic Battle with Apple and Google
21. September 2020 Information Consulting, Outreach, Bereitstellung von Forschungsinfrastruktur
18. September 2020 Unsterblichkeit, ewiges Glück und göttliche Schöpfungsfähigkeit als die großen Projekte des 21. Jahrhunderts
17. September 2020 Scouting, Entwicklung und Vermittlung von Informationslösungen
15. September 2020 Refinitiv Moves into ESG Analytics
14. September 2020 Tiefere Due-Diligence-Prüfungen von wirtschaftlich Berechtigten verlangt
11. September 2020 An der Schwelle einer neuen Zeitenwende der Aufstieg eines neuen Glaubenssystems
10. September 2020 Wie wird „Steilvorlagen“ durch Buchmesse ohne Aussteller beeinflusst?
8. September 2020 In der Melange zwischen Fake News und wissenschaftlichen Aussagen neue Chancen für die Informationswissenschaft?
7. September 2020 The Future of the APE Conference has been secured
4. September 2020 Externe Expertennetzwerke als Informationsquelle
3. September 2020 Die ersten Information Professionals
1. September 2020 Auszeichnung für Dieter Schumachers „Philosophie der Bürokratie“
31. August 2020 Budgetflexibilisierung, Mittel für Marketing und Werbung, UBs als Dritter Ort
28. August 2020 Interne Schwarmintelligenz mit smarter Lösung nutzbar machen
27. August 2020 Migranten, KMU-Mitarbeiter: Lernen, sich im Internet selbstständig zu bewegen
25. August 2020 Die richtigen Mitarbeiter finden, Ermöglichkeitskultur aufbauen
24. August 2020 Advanced Search, Tools and Visualisation – The Example of Minesoft (III))
21. August 2020 F.A.Z. Bibliotheksportal: Das Primat der Nutzerorientierung
20. August 2020 Die Leidenschaft, die hinter dem Produkt steht
18. August 2020 Advanced Search, Tools and Visualisation – The Example of Minesoft (II)
17. August 2020 Die ideale wissenschaftliche Bibliothek: Vision und Mission
14. August 2020 Informationelle Kompetenz. Ein humanistischer Entwurf
13. August 2020 Ein neuer Gigant für Patentinformationen und -dienste
11. August 2020 Warum Sie an den Steilvorlagen 2020 teilnehmen sollten
10. August 2020 2025 zentraler und nationaler Information Hub für die Lebenswissenschaften
7. August 2020 Advanced Search, Tools and Visualisation – The Example of Minesoft (I)
6. August 2020 Gemischte Bilanz für automatisierte Auskunfts- und Beratungsdienste
4. August 2020 Steilvorlagen 2020: Neue Chancen für InfoPros und Data Scientists
3. August 2020 ZB MED als nationaler Knotenpunkt in den Lebenswissenschaften
31. Juli 2020 Informationskompetenz, Demokratie und Bildung: Internationale Perspektiven
30. Juli 2020 Stiftung Preußischer Kulturbesitz vor der Zerschlagung – Was sich ändern muss
28. Juli 2020 Der Studierende will seine Materialien, und zwar sofort
27. Juli 2020 Alternative Data Brokers: Competitive Analysis
24. Juli 2020 Digitale Dienste ins Zentrum der Strategie!
23. Juli 2020 Forschungsinformationen, Digital Humanities, Kreativräume
21. Juli 2020 Alternative Data Brokers: Market Size and Market Share
20. Juli 2020 Digitalisierung als Game Changer für den Non-Profit-Sector
17. Juli 2020 Erwarten Sie mehr! Aktuelle Trends in Universitätsbibliotheken
16. Juli 2020 Alternative Data Brokers: Market Drivers and Inhibitors
14. Juli 2020 Wie KI bei Elsevier zu besseren Forschungsergebnissen führt
13. Juli 2020 Alle Herausforderungen für Bibliotheken in 2 1/2 Stunden erörtert
10. Juli 2020 Informationsinfrastruktur: Kooperation und Konkurrenz mit den Bibliotheken
9. Juli 2020 Informationskompetenz in den Bibliotheken und in der Informationswissenschaft
7. Juli 2020 Unterlassungsbescheide gegen Corona-Schnelltests
6. Juli 2020 Wissensgraphen: Wir haben die Wissenschaftskommunikation neu zu erfinden
2. Juli 2020 Wie das ZPID an seinen Herausforderungen wuchs
1. Juli 2020 Wirecard: The Blame Game about the Missing EURO 1.9 billion in Cash
30. Juni 2020 Steilvorlagen 2020: Alternative Datenquellen
29. Juni 2020 The Information Industry Impact of COVID-19: Essentials Actions Required
27. Juni 2020 Wie man mit „Information“ umgehen sollte: Das Beispiel der Medienforschung
25. Juni 2020 Perspektiven wissenschaftlicher Informationsinfrastruktur-Einrichtungen
23. Juni 2020 Maschine, übernehmen Sie! Wir Humans wenden uns interessanteren Themen zu
22. Juni 2020 The Information Industry Impact of COVID-19
19. Juni 2020 Zertfikationskurs als erster Schritt in lebenslanger Weiterbildung
18. Juni 2020 Der Mensch als die größte Katastrophe, die die Erde je heimgesucht hat
16. Juni 2020 Hasselhorn: Corona-Politik der Bundesregierung mitentwickelt
15. Juni 2020 Fusion „Steilvorlagen“ und „Datenbankfrühstück“
12. Juni 2020 Bibliotheken sollten Wissenschaftskommunikation mitgestalten
9. Juni 2020 TIB-AV-Portal: Perspektiven und Herausforderungen
8. Juni 2020 Market Leaders, 10 to Watch: Data Privacy Solutions in the Covid19-Era
5. Juni 2020 Fallbeispiele: Assistenzsystem Roboter und Indoor-Lokalisierung
4. Juni 2020 Die bibliothekarische Funktion bleibt erhalten, aber in welcher Organisationsform?
3. Juni 2020 Competitive Analysis: Data Privacy Solutions in the Covid19-Era
2. Juni 2020 Eine verlässliche Infrastruktur für wissenschaftliche Filme
29. Mai 2020 „Zukunft wissenschaftlicher Bibliotheken“: Die Beurteilung
28. Mai 2020 Data Privacy Solutions in the Covid-19 Era
26. Mai 2020 Virtualisierung gelungen!: „Zukunft wissenschaftlic
25. Mai 2020 Die Kapitulation der Informationswissenschaft vor dem eigenen Basisbegriff
22. Mai 2020 Best Practice in Wildau: Von RFID zur fluiden Bibliothek
19. Mai 2020 Nach dem radikalen Abbau der Biodiversität vor dem ökologischen Crash?
18. Mai 2020 Corona verschärft Ungleichheiten zwischen Männern und Frauen
15. Mai 2020 Forschungsethik im Forschungsdatenmanagement
14. Mai 2020 Mut und Erfahrung mit RFID, iBeacon und Pepper
12. Mai 2020 Neue MOOC-Angebote für die Informationskompetenz
11. Mai 2020 Verschwörungstheorien in Zeiten von Corona
8. Mai 2020 Für Vielfalt, Diversifizierung und Unterschiedlichkeit in Bibliotheken
7. Mai 2020 Wie man eine sinnvolle Medienkritik mit wahnwitzigen Übertreibungen vernichten kann
5. Mai 2020 Risiken in Lieferketten durch Coronavirus vervielfacht
4. Mai 2020 Verändert Open Access die Welt?
30. April 2020 „Tollste Bibliothek des Universums“, Teil 2
28. April 2020 Gegen Fake News Rückkehr zu alten journalistischen Tugenden geboten
27. April 2020 Die „Zukunft wissenschaftlicher Bibliotheken“ findet trotzdem statt – nunmehr virtuell
24. April 2020 Was Wissenschaft und Praxis voneinander lernen können
23. April 2020 „Tollste Bibliothek des Universums“
21. April 2020 Fake News und Corona: Wie herausfinden
20. April 2020 Rote Bibliotheken: Die Aufzucht eines sozialistischen Bibliothekars misslang
17. April 2020 COVID-19’s Impact on the Data, Information, and Analytics Industry
16. April 2020 Die Corona-Krise ist auch eine Krise der Information
14. April 2020 Unter der Bedrohung von Corona sind wir alle zusammengerückt
9. April 2020 Stadtteilbibliothek Köln-Kalk: Von der Vision zur Realität
7. April 2020 Warum ist die Corona-Krise nicht die Stunde der Bibliotheken?
6. April 2020 Von Otto bis Zeiss: Wie digitale Transformationen gelingen
3. April 2020 Was Wissenschaft und publizistische Praxis voneinander lernen können
2. April 2020 Stadtbibliothek Köln: Proaktiver Player in der Stadtgesellschaft
31. März 2020 Die Grenzen der DDR-Diktatur durch Unvermögen ihrer Handlungsträger
30. März 2020 Bewertung von Quellen und kritisches Denken
27. März 2020 Wo sollen die Dozenten für Fachhochschulen herkommen?
26. März 2020 Rote Bibliotheken: Warum der Widerstand ambivalent zu bewerten ist
24. März 2020 Von der Unwiderstehlichkeit der Inhalte
23. März 2020 Chancen für InfoPros in der Corona-Krise
20. März 2020 Stadtbibliothek Hattingen: Einladung zum langen Verweilen
19. März 2020 Orientierungen unsere Bibliotheken an USA, nicht an unserer Vergangenheit!
17. März 2020 The Global Market Leader in Legal News as an Disruptor
16. März 2020 Ein Blick auf die Informationsbranche in den Zeiten von Corona
13. März 2020 Die Bedeutung von Home Office in Zeiten von Corona
12. März 2020 Wissenschaftsgemeinschaft vernachlässigt Kernaufgabe des Transfers
10. März 2020 „Good Practices“ im Forschungsdatenmanagement
9. März 2020 Google weit von Minimalanforderungen an Retrievalsysteme entfernt
6. März 2020 Nach Bombenfund und Evakuierungen: „Zukunft wissenschaftlicher Bibliotheken?!“ wird nachhgeholt
5. März 2020 Corona: Zwischen 200 nachgewiesenen Fällen und dem völligen Shutdown
3. März 2020 Kritische Wissenschaftskompetenz als Teil der Informationskompetenz
2. März 2020 Eine Zivilgesellschaft, die den mündigen Bürger verhindert
27. Februar 2020 Wie die unselige Symbiose aus Medien und Politik einen Sieg über den Terror beinahe unmöglich macht
26. Februar 2020 Digitale Vorreiter erlangen in Deutschland relative Mehrheit
25. Februar 2020 „Information Assessment“ und „Informationskompetenz“ als Alleinstellungsmerkmale der Informationswissenschaft
21. Februar 2020 Wie die Selbstentmachtung der US-Regierung die Überwachung der Menschheit ermöglichte
20. Februar 2020 A Tool to Empower Minorities – Part II
18. Februar 2020 Bibliotheken in einer smarten Nation
17. Februar 2020 New AI Regulations on the Horizon
14. Februar 2020 Social Media. A Tool to Empower Minorities in American Politics
13. Februar 2020 Forschungsdatenbanken zur Evaluierung von Forschungsleistungen wenig geeignet
11. Februar 2020 Trends des Jahres: 2019 zurück bis 1986
10. Februar 2020 „Der andere Heimatroman“ in zweiter Auflage
6. Februar 2020 Informationswissenschaft: Doch einen angemessenen Praxisbezug?
5. Februar 2020 Outsell Unternehmen des Jahres 2019/2020
4. Februar 2020 Flughäfen der Zukunft: 10 Prognosen
3. Februar 2020 InfoPros can stay two steps ahead of AI
31. Januar 2020 Die wichtigsten Ankündigungen für 2020, und warum sie so wichtig sind
30. Januar 2020 Ausbau des Studiums in Richtung Data Science und Digital Business Management
28. Januar 2020 InfoPros als Berater der Berater für die wirklich wichtigen Fragen
27. Januar 2020 Wie KI die Recherche verändern wird: Vier Trends
24. Januar 2020 Ein hinreißendes Herz für Autoren und ihre Werke
23. Januar 2020 Zukunft der APE: Arnoud de Kamp organisiert den Übergang
21. Januar 2020 „Wider eine Überschätzung der Leistungen der Informationswissenschaft“
20. Januar 2020 „Personal Branding: „Seien Sie wie Sie sind. Es kommt sowieso raus.“
19. Januar 2020 100 Anmeldungen für „Zukunft wissenschaftlicher Bibliotheken“
17. Januar 2020 Bestände zur Kulturlandschaft Siebenbürgen in Deutschland und Südosteuropa
15. Januar 2020 : Männer des Jahres: Die Rebellen der Informationswissenschaft
9. Januar 2020 : Was 2019 der KI brachte
8. Januar 2020 : Trend des Jahres: Digitale Transformation
20. Dezember 2019 : Know-Your-Customer-Prozess effizienter gestalten
19. Dezember 2019 : Informationskompetenz: Die überzogenen Ansprüche der Infowissenschaft
17. Dezember 2019 : Bessere Therapien durch Soziale Medien?
16. Dezember 2019 : The Next Generation of Metrics for Scholarly Communications
13. Dezember 2019 : Open Access als Geschäftsmodell – Perspektiven der Governance von Open Access
11. Dezember 2019 : WTI: Unter neuem Eigentümer Schritte in Richtung Data Science
10. Dezember 2019 : Die Informationswissenschaft als Hügellandschaft mit „Stand-alone-USPs“
9. Dezember 2019 : Wie authentisch dürfen Mitarbeiter in Unternehmen sein?
6. Dezember 2019 : Governance von Forschungsinfrastruktur am Beispiel von Open Access
5. Dezember 2019 : Steilvorlagen: Weiter „Praxis, Praxis, Praxis“
3. Dezember 2019 : Wider die informatonelle Entmündigung
2. Dezember 2019 : Inforrmations- und Kommunikationsring der Finanzdienstleister: Das Ende
29. November 2019 : Internet-Nutzer: Unbelehrbar in der Echokammer?
28. November 2019 : Gemeinsame Erfolge bei Research-Großprojekten
26. November 2019 : Journalisten und Lehrer im Informationsdschungel Internet
25. November 2019 : Googles Qantencomputer: Ein Sputnik-Moment in der Informationstechnologie?
22. November 2019 : Über Metadaten Fake News erkennen?
21. November 2019 : Scholarly Communications at a Tipping Point: A Biritsh Roadmap to the Future
19. November 2019 : Die Informationswissenschaft hat ein strukturelles, nicht inhaltliches Problem
18. November 2019 : Darknet: Wieviel Manipulation enthält die dunkle Seite des Web?
14. November 2019 : Wie die Informationswissenschaft kommerzielle Suchmaschinen erforschen sollte
13. November 2019 : Politische Forderungen und Responses der Informationswissenschaft: Ein Abgleich (2)
12. November 2019 : Lob für Strukturierung, Vielfalt, Praxisrelevanz und spezifische Informationsbereiche
11. November 2019 : „Zukunft wissenschaftlicher Bibliotheken!“ – Fachtagung mit Open Password
8. November 2019 : Steilvorlagen: Noten 1,5 für Mary Ellen Bates und Endler-Jobst
7. November 2019 : Creating a Culture Supporting AI Success
5. November 2019 : User Experience und Informationswissenschaft – Anwendungsfall, Teilgebiet, Nachbardisziplin?
4. November 2019 : Inwieweit kommt die Informationswissenschaft politischen Anforderungen nach?
31. Oktober 2019 : Wie die Informationswissenschaft eine Zukunft haben kann
29. Oktober 2019 : User Experience: Forschung und Lehre an deutschsprachigen Hochschulen
28. Oktober 2019 : Google vs. France: Fighting the „Link Tax“
25. Oktober 2019 : Die kritischen Punkte von Open Access
24. Oktober 2019 : Einsatz von Künstlicher Intelligenz wird selbstverständlich
22. Oktober 2019 : Jeder zweite Onliner nutzt digitale Verwaltungsdienste
21. Oktober 2019 : Trennung zwischen Bibliotheks- und Infowissenschaft rückgängig machen!
18. Oktober 2019 : Für InfoPros mit Phantasie, Kreativität und Fingerspitzengefühl
17. Oktober 2019 : User Experience und Infomationswissenschaft in Deutschland
15. Oktober 2019 : Competitive und Market Intelligence gehen an die Hochschule
14. Oktober 2019 : Best Practice, Use Cases, Strategien. Die „Steilvorlagen“ am Donnerstag
11. Oktober 2019 : Transdisziplinärer Dialog zwischen Informationswissenschaft, Philosophie und Soziologie
10. Oktober 2019 : Online Marketing: Ein Lehr- und Forschungsgebiet für die Informationswissenschaft?
8. Oktober 2019 : Das Geheimnis von Boris Johnsons kommunikativer Wirkung
7. Oktober 2019 : Best Practice in Bibliotheken: Aufruf zu Beiträgen!
4. Oktober 2019 : Suchwortvermarktung, Suchmaschinenoptimierung, Social Media Marketing
1. Oktober 2019 : Mit Doppelstrategie aus automatisierter Recherche und hcohwertiger Analytik zu zweistelligen Wachstumsraten
30. September 2019 : Wie Bedeutung und Sichtbarkeit der Infowissenschaft zu erhöhen sind
27. September 2019 : DIMDI: Die Kaiserjahre in Köln
26. September 2019 : Online Marketing als Lehr- und Forschungsfeld der Informationswissenschaft
24. September 2019 : Personal Branding: Jeder hat so viel zu erzählen!
23. September 2019 : Infowissenschaft und Bibliotheken haben glänzende Zukunft – aber nur gemeinsam!
20. September 2019 : Amazon vs. führende Weltverlage im Copyright-Streit
19. September 2019 : Zukunft der Informationswissenschaft – Hat die Informationswissenschaft eine Zukunft?
17. September 2019 : Curriculumsentwicklung an der HTW Chur
16. September 2019 : Steilvorlagen: Mit optimaler Bereitstellung von Daten zu besseren Analysen
13. September 2019 : Aufstieg zur Europe´s No1 in Biosciences Information
12. September 2019 : „Keine Bibliothek ohne Leidenschaft“
10. September 2019 : Der Fachbereich Digital Science an der HTW Chur
9. September 2019 : Mary Ellen Bates: Chancen für Information Professionals in der Welt Künstlicher Intelligenz
6. September 2019 : Zwei neue Gold-Sponsoren bei „Steilvorlagen“
4. September 2019 : Digitale Transformation und Kulturwandel bei BMW
3. September 2019 : Veränderung und Kontiunität bei Studiengängen an der HTWK Leipzig
2. September 2019 : Bibliothekare: Verwaltungsbeamte oder so mutig wie ihre Autoren?
29. August 2019 : Bundesbürger halten Datenschutz für wichtiger, aber kümmern sich nicht drum
28. August 2019 : Ein großer Pionier der Datenbanbranche wird 50
27. August 2019 : Einen gesellschaftlichen Diskurs für Informationskompetenz und Demokratie!
26. August 2019 : Personal Branding: Marke + Relevanz + Verständlichkeit + Präsenz + fehlende Penetranz + Durchhaltevermögen = Erfolg
23. August 2019 : Spannungsfeld zwischen Informationswissenschaft und Informatik
22. August 2019 : Bürger und Kunden als Mitgestalter von Bibliotheken und Kommunalverwaltungen
20. August 2019 : Bürger, Suchverfahren und Analyse-Algorithmen in der politischen Meinungsbildung
19. August 2019 : Dem großen Anspruch der Bibliotheken nicht nur in ihren Konzepten gerecht werden!
16. August 2019 : Lehr- und Lernraumforschung im Kontext der Informationswissenschaft
15. August 2019 : A Comprehensive View of First Half Events in the International Arena
13. August 2019 : Informationswissenschaftler dabattieren in Berlin über die Zukunft ihrer Disziplin
12. August 2019 : Im Kampf gegen große Fälscherfabriken helfen Behörden nur bedingt
9. August 2019 : Wie man sich in Volatilität, Unsicherheit, Komplexität und Ambiguität behauptet
8. August 2019 : Anwendungsboom in der KI noch vor dem Take-off
6. August 2019 : Was an den deutschsprachigen Hochschulen tatsächlich geforscht wird – Eine empirische Studie
5. August 2019 : Wie sich die Informationswissenschaft in der digitalen Transformation behauptet
2. August 2019 : Libra: Eine vielversprechende Währung in den falschen Händen
1. August 2019 : Siegeszug von Blockchain und Visualisierung
30. Juli 2019 : Was tatsächlich an den deutschsprachigen Hochschulen gelehrt wird
29. Juli 2019 : Die Düsseldorfer Informationswissenschaft lebt weiter
25. Juli 2019 : Aktuelle Entwicklungen und Herausforderungen der Informationswissenschaft: Eine empirische Studie
24. Juli 2019 : Das Rennen um die Eroberung des Marses
23. Juli 2019 : Die Mondlandung: Eine Kosten-Nutzen-Analyse
22. Juli 2019 : Die Verbreitung der Düsseldorfer Informationswissenschaft
19. Juli 2019 : Wissensbasierte Informationsflüsse: Wissenschaftliche Bibliotheken im Transformationsprozess
18. Juli 2019 : KI-Anwendungsboom – und doch bleibt die Patentrecherche eine Kunst
17. Juli 2019 : KI: Der unaufhaltsame Aufstieg des Wissensgraphen
16. Juli 2019 : 10 Empfehlungen, die aus Ihrem Geschäft eine Success Story machen
12. Juli 2019 : ZPID: Ausbau zum Universalanbieter für Infrastrukturbedarf der Psychologie
11. Juli 2019 : Der Open Research Knowledge Graph
9. Juli 2019 : Wie Journalismus im Netz Geld verdient: Das Beispiel BurdaForward
8. Juli 2019 : Zivilgesellschaftliche Plattformen für Europa!
5. Juli 2019 : Vor Revolution der wissenschaftlichen Kommunikation mit Knowledge Graph?
4. Juli 2019 : Rent Vs. Own: The $2 Billion Reference Data Question
2. Juli 2019 : Forschung und bibliothekarischer Kernbereich werden einander bedingen
1. Juli 2019 : Die Alleinstellungsmerkmale der InfoPros für KI
28. Juni 2019 : News: Actionable Insights by Advanced Analytics
27. Juni 2019 : Zur Selbstorganisation wissenschaftlicher Bibliotheken
25. Juni 2019 : Nach der „Kulturrevolution“ in den Leibniz-Einrichtungen nur noch Lob und positive Bewertungen?
24. Juni 2019 : Best Practice in der Informationsvermittlung
21. Juni 2019 : Neue Informationsdienste für neue Bedürfnisse
18. Juni 2019 : Deutsche KI-Vorteile bei Produktion, Mobilität und medizinische Forschung
17. Juni 2019 : Warum Blogs, Podcasts und Videos für InfoPros ein Muss werden
14. Juni 2019 : Vollständiger Zugang zur wissenschaftlichen Information!
13. Juni 2019 : Mit Wissensgraphen Lücke zwischen Daten und Perspektiven der Nutzer schließen
11. Juni 2019 : 1986 – 2019: Open Passwords Trends des Jahres
7. Juni 2019 : InfoPros: Get a Strategic Seat at the Top Table!
4. Juni 2019 : Reputation wissenschaftlicher Bibliotheken als Ort für Produktion neuen Wissens verteidigen!
3. Juni 2019 : Deutschlands Cyber Security: Sinkende Readyness und steigende Schäden
29. Mai 2019 : One of the Highest Client Retention Rates by Unlimited Customer Service
28. Mai 2019 : ConTech, the only conference about the intersection of content and technology
27. Mai 2019 : Steilvorlagen: Das beste Programm, das wir jemals hatten
24. Mai 2019 : Quantentheorie und Alltagspraxis: Was lässt sich übernehmen?
23. Mai 2019 : Naturwissenschaft und Evolution – Die Rolle der Informationswissenschaft
21. Mai 2019 : Bundesbürger jetzt 50 Stunden die Woche online
20. Mai 2019 : Mit dem richtigen Mindset auf Erfolgskurs
17. Mai 2019 : Minesofts Erfolgsgeheimnis: All the while listening to clients’ feedback
16. Mai 2019 : Die Quantentheorie und die Informationsbranche
14. Mai 2019 : Informationswissenschaft: Über den Tellerrand auf andere Disziplinen schauen!
13. Mai 2019 : Subito: Neue Schranken und doch keine Verbesserung?
10. Mai 2019 : Information Professional des Jahres: Ann Chapman
9. Mai 2019 : Anna Knoll widerspricht Bern Jörs
7. Mai 2019 : InfoPros: Eine Excel-Liste großer Taten immer in der Schublade
6. Mai 2019 : Was die anderen Disziplinen für die Informationswissenschaft tun können
2. Mai 2019 : Was können Bibliotheken gegen ihr allmähliches Verschwinden in der Öffentlichkeit tun?
30. April 2019 : Statista: Digital Economy Compass 2019 erschienen
29. April 2019 : Löst die traditionelle Informationswissenschaft weitgehend auf!
26. April 2019 : Alles schwieriger durch Brexit? Geldwäsche, Bestechnung, Terrorismusfinanzierung
24. April 2019 : Kritik der In(formations)kompetenz
23. April 2019 : The Key to Advancing Scholarly Communication
17. April 2019 : Theorielosigkeit, keine Problemlösungen, Ausbildung zu Universal-Dilettanten
16. April 2019 : Proaktives Handeln in der Digitalisierung – Ein Brief an die Branche von Michael Klems
15. April 2019 : Julian Assange und die nur teilweise funktionierende Peer-Review-Kultur der Qualitätsmedien
11. April 2019 : „Wer bei KI nicht mitmacht, hat schon verloren“
10. April 2019 : Die gefährlichen Ideologen von Silicon Valley
9. April 2019 : Leipziger Buchmesse: Eine Lesefest für die ganze Stadt
8. April 2019 : In(formations)kompetenz versus Datenkompetenz – Von Bernd Jörs
5. April 2019 : Bibliotheken als Sensorium für notwendig gewordene Veränderungen
3. April 2019 : International Open Science Conference: Es geht um die Umsetzung!
2. April 2019 : Nehmt Mark Zuckerberg beim Wort (außer bei der DSGVO)!
1. April 2019 : Die Infowissenschaft ist tot, es lebe die Datenwissenschaft!
28. März 2019 : Storytelling: Mehr Hype als Substanz
27. März 2019 : EU-Parlament beschließt inhaltliche Verarmung des Internets
26. März 2019 : Digitalisierung versus Menschenwürde
25. März 2019 : Eroberung der Tiefsee und fremder Planeten durch Künstliche Intelligenz
21. März 2019 : Führung einer verunsicherten Belegschaft durch Charisma
20. März 2019 : A Farewell to British Pragmatism?
19. März 2019 : Storytelling: Fake News oder Zukunft des Journalismus?
18. März 2019 : InfoPros wandeln sich zu Textgestaltern, Podcastproduzenten und Visualisierungskünstlern
15. März 2019 : Von Mitarbeitern mit einem unersättlichen Bedürfnis nach Lob – Altruismus lohnt sich, aber nur in Grenzen
14. März 2019 : Von Abenteurern im Geiste, die unser Wissen vergrößern
12. März 2019 : Diskriminierung der Wissenschaftler und Sloppy Research
11. März 2019 : PATINFO 2019: Alles im Zeichen Künstlicher Intelligenz
8. März 2019 : Walther Umstätter 1941 – 2019
7. März 2019 : Opportunities for Information Providers: Trust is the New Algorithm
5. März 2019 : Zukunft der Information Science: Praxis, Forschung und Lehre
4. März 2019 : ETH Zürich als Benchmark für deutschsprachige Bibliotheken?
1. März 2019 : Trust in AI revolution
28. Februar 2019 : Gleich zwei Steuermänner der Branche gehen von Bord
26. Februar 2019 : Guido Schenk: „We must accept finite disappointment, but never lose infinite hope“
25. Februar 2019 : Hat die Informationswissenschaft eine Zukunft?
22. Februar 2019 : Reform des Europäischen Urheberrechts: Noch mehr unsinnige Bürokratisierung
21. Februar 2019 : KI in der Telekommunikation: Arbeitsplatzverluste und Individualisierungschancen
19. Februar 2019 : Die Kunst der Recherche – was bleibt und was sich dramatisch verändert hat
18. Februar 2019 : Coworking als Arbeitsmodell für Information Professionals
15. Februar 2019 : Daten-Plattformen für KI-Analysen: Eine Win-Win-Situation
14. Februar 2019 : Der InfoPro als Mittler zwischen KI-Anbietern und Management
12. Februar 2019 : How the Rise of AI will Impact Communication Professionals
11. Februar 2019 : Open Password, Outsell und BIIA wählen KI und „Streben nach Sicherheit“ zu Trends des Jahres
7. Februar 2019 : Levitsky/Ziblatt: Wie Demokratien sterben
7. Februar 2019 : 2018/2019: Trust is the New Algorithm
5. Februar 2019 : Sander-Beuermann: Was bleiben muss – Freier Wissenszugang und Schutz vor Datenkraken
4. Februar 2019 : Die radikale Modernisierung des ZBW
1. Februar 2019 : Sander-Beuermann zieht sich zurück: Rückblick und Ausblick
31. Januar 2019 : 100 Jahre ZBW: DIE Forschungsbibliothek der Wirtschaftswissenschaften
29. Januar 2019 : Von Bochum nach Vietnam: Entwicklungshilfe von Bibliothek zur Bibliothek
28. Januar 2019 : Smart Cities im internationalen Vergleich
25. Januar 2019 : Nach Relotius: Neue Chancen für Information Professionals
23. Januar 2019 : Lagebild zur Digitalisierung: Jeder dritte Deutsche ein digitaler Vorreiter
22. Januar 2019 : Vor einem Blockbuster-Jahr in der App Economy
21. Januar 2019 : Gegen den Content-Schock Sprachsteuerung, Podcasts und Videos
18. Januar 2019 : Künstliche Intelligenz: Deutschland mit Taschengeldern gegen USA und China
16. Januar 2019 : Legal Tech: Zur Digitalisierung im Rechtswesen
15. Januar 2019 : Warum die bisherige Selbstkritik der Qualitätsmedien zu kurz greift
14. Januar 2019 : SPIEGEL und Qualitätsmedien in der Krise: Neue Chancen für InfoPros
11. Januar 2019 : Mehr Zivilcourage und ziviler Ungehorsam und gegen die DGSVO
9. Januar 2019 : Appell an die Zivilgesellschaft: Nehmt die DSGVO erst gar nicht zur Kenntnis!
8. Januar 2019 : Künstliche Intelligenz: Vor dem Durchbruch in der Informationsbranche
7. Januar 2019 : Warum unsere Branchenberichterstattung nicht erfolgreich ist
19. Dezember 2018 : Ideale Voraussetzungen bei Infoanbietern und Infozentren für KI-Engagement
18. Dezember 2018 : Der InfoPro als treibende Kraft bei KI-Anwendungen
17. Dezember 2018 : Die Highlights in Open Password 2018
14. Dezember 2018 : Plan S: Weitere Schritte für europaweites Open Access
12. Dezember 2018 : Die Desinformationskampagne Russlands gegen den Westen
11. Dezember 2018 : China: Durch „Social Scoring“ zur Hamonischen Gesellschaft
10. Dezember 2018 : InfoPros: Das digitale Waterloo als Chance
7. Dezember 2018 : Weißbuch „Zukunft der Kreditinformation“
5. Dezember 2018 : Während die Zahl smarter Städte zunimmt, geht der „free flow of information“ weltweit zurück
4. Dezember 2018 : IKT-Standort Deutschland legt im weltweiten Vergleich zu
3. Dezember 2018 : Ziehen Sie Ihre Marathonschuhe an und laufen Sie jetzt!
30. November 2018 : TIB, DIPF und ZPID positiv evaluiert
29. November 2018 : CeBit macht dicht: Lehren für die Informationsbranche
28. November 2018 : Wie sich die Informationswissenschaft der „Fake News“ annehmen kann
27. November 2018 : DGSVO tötet zivilgesellschaftliches Engagement
26. November 2018 : Marketing: Warum der „direkte Weg zum Erfolg“ ins Nirgendwo führt
23. November 2018 : Fake News als informationswissenschaftliche Herausforderung
21. November 2018 : ZB MED soll Forschungsdateninfrastruktur koordinieren
20. November 2018 : In einer Zeit der Furcht und Selbstzensur ein Journal für kontroverse Ideen
19. November 2018 : Fehlende Kundenzentrierung als Defizit der Information Professionals
16. November 2018 : Von Daten zu Einsichten im Versicherungsmarkt
14. November 2018 : Die Aufgabe der Bibliotheken ist die Erleuchtung
12. November 2018 : Die drei wichtigen Kernkompetenzen zur Markenbildung als InfoPro
9. November 2018 : Warum Informationskompetenz ein Muss ist
7. November 2018 : 40 Jahre GBI-Genios in Bildern
6. November 2018 : Wo wir die Künstliche Intelligenz weder haben noch benötigen
5. November 2018 : EXIT: Strategien für den selbstbestimmten Ausstieg
2. November 2018 : „Steilvorlagen 2017“ war sehr gut, aber „Steilvorlagen 2018“ war noch besser!
31. Oktober 2018 : „Steilvorlagen“: Auf jede Kritik vier positive Einschätzungen
30. Oktober 2018 : Studierende in den Dialog der Branche einbeziehen!
29. Oktober 2018 : Gemeinsam die breite Öffentlichkeit erreichen!
25. Oktober 2018 : Hochschulen und Infowissenschaft in existenzieller Krise
23. Oktober 2018 : Recherche-Tools für die sichere Recherche
22. Oktober 2018 : 98% der Teilnehmer würden „Steilvorlagen“ weiteempfehlen
19. Oktober 2018 : Überleben in der Aufmerksamkeitökonomie
17. Oktober 2018 : ZB MED schärft Forschungsprofil
16. Oktober 2018 : Mit Textmining Stimmungsbilder zu komplexen Themen
15. Oktober 2018 : Steilvorlagen für den Unternehmenserfolg in Bildern
10. Oktober 2018 : Wissenschaftliche Dienste des Bundestages: Offener Blick auf komplexe Problemfelder
9. Oktober 2018 : Ein „Innovation Center“ in der Mitte von Merck
8. Oktober 2018 : Gute Erfolgschancen im High-Quality-Wettbewerb
3. Oktober 2018 : Towards Affordable Prices in the Education Information Market
2. Oktober 2018 : Patentinformationen im 21. Jahrhundert: Neues Profil für den Rechercheur
1. Oktober 2018 : 4 Jahre Wandel für Competitive Intelligence
28. September 2018 : Bibliotheken: Fake News als Herausforderung annehmen
27. September 2018 : Können Philosophen zum Unternehmenserfolg beitragen?
25. September 2018 : Wie aus unstrukturierten Daten Wettbewerbsvorteile entstehen
24. September 2018 : Hat Data Science die Informationswissenschaft überflüssig gemacht?
20. September 2018 : Business Intelligence: Was ist das beste Visualisierungstool?
19. September 2018 : Schritte einer optimalen Recherche
17. September 2018 : Europäisches Urheberrecht: Ein Albtraum nach Orwell
16. September 2018 : Monika Heim: Existenzsicherung durch Integration elektronischer Produkte in Prozesse der Branken
13. September 2018 : Steilvorlagen: Beschleunigung, Verunsicherung, Konnektivität und Distanz
12. September 2018 : Vom Siegeszug der Echtzeit-Informationen zum Aufstieg virtueller Währungen
11. September 2018 : Deutschland im Cyber-Krieg mit Russland, China, Iran und Türkei
10. September 2018 : Change Management für Mitarbeiter von InfoZentren
7. September 2018 : Sabine Graumann: Gute Chancen für den beruflichen Nachwuchs
6. September 2018 : Insourcing der Recherche und Beratung der Geschäftsleitung durch IP-Intelligence
4. September 2018 : Frank Schätzing: Bedrohung durch Supertechnologien
3. September 2018 : Swiss Re: Punkten mit Kundennähe und Kundenzufriedenheit
31. August 2018 : Sabine Graumann: Eine Zeitreise entlang der Geschichte der Fachinformation
30. August 2018 : Reformen in Aus- und Weiterbidung: Was wird aus Competitive Intelligence?
29. August 2018 : Israel: Bibliotheken als Orte des Ausgleichs zwischen Arabern und Juden
28. August 2018 : Unser Leben und Arbeiten 2030
27. August 2018 : Von der Kunst, auf dem Markt entdeckt zu werden
24. August 2018 : EU´s Overkill of Data Protection
23. August 2018 : Digitale Manipulationen: Angriffe auf das Immunsystem unserer Demokratie
21. August 2018 : Der Cyber War gegen Russland und China
20. August 2018 : Reformen in Aus- und Weiterbildung: Noch größere Dringlichkeit
17. August 2018 : Use libraries to get human again
16. August 2018 : PATINFO: Mehr Intelligenz für Recherchewerkzeuge
15. August 2018 : Competitive Intelligence als Kunst und Wissenschaft: Fortschritte in Tools und Skills
13. August 2018 : D&B zieht sich vor Demütigungen an der Börse zurück
10. August 2018 : Praktikum zur Sommerzeit in (kühlen?) Archiven
8. August 2018 : Die „Open Access“-Bewegung ist leider verstorben – ein Nachruf
6. August 2018 : International Corner: Bilanz des ersten Halbjahres – von Anthea Stratigos
6. August 2018 : Weiter systematische Verwechslung von Fachinformationseinrichtungen mit Forschungsinstituten
3. August 2018 : Peter Müller-Bader gestorben
1. August 2018 : Kein einziger, der sich dem Untergang des DBI entgegenstemmte
30. Juli 2018 : DBI: „Mission Impossible“ führte zum Untergang
27. Juli 2018 : Lankes: Die Bibliothek als verlängerter Arm ihrer Community
26. Juli 2018 : Die Zukunft der Bibliotheken nach Rafael Ball
24. Juli 2018 : Qatar: Wissenschaftsgesellschaft als Erfolgsgeschichte
23. Juli 2018 : Qatar: Eine Wissensgesellschaft entsteht
20. Juli 2018 : Die richtige Social-Media-Strategie
19. Juli 2018 : STN International vor dem langfristigen Aus?
18. Juli 2018 : Die nächste Schlüsseltechnologie: Quantencomputer
17. Juli 2018 : Die Bibliotheken als Community- und Peer-Review-Anbieter
16. Juli 2018 : Die Chancen der Hosts zum Community Building
13. Juli 2018 : Dow Jones: Stronger Reputations by Compliance
12. Juli 2018 : Vermittlung von Digital Literacy als neue Kernkompetenz
11. Juli 2018 : Sabine Graumann ist Information Professional des Jahres
10. Juli 2018 : Musikwirtschaftsgipfel: Durch Digitalisierung und kommendes Urheberrecht unter Druck
9. Juli 2018 : InfoPros, sitzend auf publizierbaren Schätzen
6. Juli 2018 : UrWissG: Bibliotheken sind nicht die Wächter des Urheberrechts
5. Juli 2018 : Steilvorlagen: Mehrwerte schaffen trotz massivem Widerstand
3. Juli 2018 : Wir halten Peter Müller-Bader in Ehren!
4. Juli 2018 : OA-Strategie Berlin, OA-Monitor, Nationaler OA-Kontaktpunkt
2. Juli 2018 : InfoPros wie die Nationalelf vor dem Abstieg in die Zweitklassigkeit?
29. Juni 2018 : Transforming Content through Data Science
28. Juni 2018 : Pioniere und digital Zurückgebliebene unter Deutschlands Kommunen
27. Juni 2018 : Kleiner Verlag „Verlag für Bibliotheken“ ganz groß
26. Juni 2018 : Mit Big Data zur 4P-Medizin: Präventiv, personalisiert, präzise und partizipativ
25. Juni 2018 : Die InfoPros und das Leistungsschutzrecht der Verleger
21. Juni 2018 : 40 Jahre GBI: A Touch of German Dream is Going On
20. Juni 2018 : Bibliotheken und Verlage: Ziemlich beste Feinde – Ein politisches Fazit des Bibliothekartages
19. Juni 2018 : Steilvorlagen 2018: Turning Information Complexity into Simplicity
18. Juni 2018 : Das Upgrading der InfoPros zu Beratern
15. Juni 2018 : Loneliness and Depression by Digitalization
14. Juni 2018 : EU-Urheberrechtsreform kontra Anbietervielfalt und Open Access
12. Juni 2018 : FAZ-Archiv: Neue Angebote nach den Grundsätzen des Urheberrechts
11. Juni 2018 : Hätte sich die DSGVO aufhalten lassen?
8. Juni 2018 : Zeit für ethische Unternehmensführung
7. Juni 2018 : Informationressourcen für Bibliothekare und Informationsspezialisten
5. Juni 2018 : Inspired by Lankes: Neue Trends in Universitätsbibliotheken
4. Juni 2018 : Datenschutzbehörden nehmen Informationsbranche ins Visier
30. Mai 2018 : Nach 24 Stunden DSGVO mehr als 300 geschlossene Blogs, Foren und Websites
29. Mai 2018 : Stolpern wir der Digitalen Euthanasie entgegen?
28. Mai 2018 : Was die DSGVO den Gewerbetreibenden und den in der Zivilgesellschaft Engagierten antut
25. Mai 2018 : DFB-Scout Siegenthaler warnt vor wachsenden Aggressivitäten in Business und Sport
24. Mai 2018 : Smart Contracts als Alternative zu Blockchain
22. Mai 2018 : Noch drei Tage bis zur DSGVO: Lasst die Kleinen in Ruhe!
18. Mai 2018 : Super CI-Konferenz auf deutschem Boden
17. Mai 2018 : ZB MED mit faktischer Dreierspitze
15. Mai 2018 : Werden Sie „merkwürdig!“
14. Mai 2018 : Europäische Unternehmen weiter im Aufschwung
11. Mai 2018 : Inmitten einer neuen Medienkatastrophe die Entdeckung des Menschen als Wetware
8. Mai 2018 : Which Management Strategy for Risk and Compliance?
8. Mai 2018 : Keine Gefälligkeiten mehr! Ihre Leistungen sind etwas wert!
5. Mai 2018 : Digitalisierung und Disruption: Das Ende der Rationalität
3. Mai 2018 : Wie geben wir dem „Schimpansen in uns“ eine Banane?
2. Mai 2018 : Dietrich Rebholz-Schuhmann neuer Direktor der ZB MED
27. April 2018 : Bitcoin vor dem Crash
26. April 2018 : Open Access und Transparenz im wissenschaftlichen Publizieren
24. April 2018 : Influencer und Blogger verdrängen Journalisten als wichtigste Zielgruppe für PR
22. April 2018 : Sind wir die Busy-Busies, die nichts gebacken bekommen?
20. April 2018 : Outsells erste internationale Produktevaluierung für Open Password
19. April 2018 : Große Heterogenität unter Market-Intelligence-Experten
17. April 2018 : Die heimische Kreativwirtschaft unter internationalem Druck
16. April 2018 : InfoPro-Veranstaltungen in Deutschland: Was jetzt schon geht
13. April 2018 : Von den USA lernen: Zielgruppengerechte Veranstaltungen für InfoPros
12. April 2018 : Die sieben Todsünden von Google Books
10. April 2018 : London Info International positioniert sich neu
9. April 2018 : Meine großen Ziele für 2018 und ein erstes Fazit nach 100 Tagen
6. April 2018 : London Info International: Die Innovationen für 2018
5. April 2018 : Neue Aufgabenbereiche für InfoPros: Evaluierung, Visualisierung und CI
3. April 2018 : Wie das Goldene Zeitalter der Branche verdaddelt wurde
28. März 2018 : Die Rückkehr der Zensur nach Russland und den USA
27. März 2018 : Bibliothekarin des Jahres: Helga Schwarz
26. März 2018 : Ihre Kommunikationsstrategie als Puzzlespiel
23. März 2018 : Anthea Stratigos zum Facebook-Skandal
22. März 2018 : Ein Kompetenzprofil für Wissensmanager
20. März 2018 : Social-Media-Influencer finden: Relevanz, Glaubwürdigkeit, Beständigkeit, Engagement und Netzwerk
19. März 2018 : Wie Sie in Ihrem Markt der Erste werden!
16. März 2018 : Bibliothekare unter der Knute der zaristischen, sowjetischen und putinischen Zensur
13. März 2018 : Open Access und Open Science nachhaltig machen
12. März 2018 : Warum Sie für andere Leute etwas tun sollten!
9. März 2018 : Wie InfoPros Dark Data zähmen
8. März 2018 : Befürchtungen der SoWi-Community kommen in den Landtag
6. März 2018 : Internationale Informationsanbieter: Auf digitale Transformation schlecht vorbereitet
5. März 2018 : Mary Ellen Bates: 400 Stunden bis zum ersten Kunden
2. März 2018 : Stirbt die E-Mail auch im beruflichen Traffic aus?
1. März 2018 : Silke Bromann: Über riesige Distanzen bleiben Face-to-Face-Kontakte unendlich wichtig
27. Februar 2018 : Was Michael Klems und Steven Spielberg gemeinsam haben
26. Februar 2018 : Big Data und Code bringen InfoPros in Not
23. Februar 2018 : Buch des Jahres: Erwarten Sie mehr von Richard David Lankes
22. Februar 2018 : LII: Disruption, Fake News und die Verführbarkeit der Nutzer
20. Februar 2018 : Digital Disruption für Bundesliga vonnöten
19. Februar 2018 : Den InfoPros konnte nichts Besseres passieren als Google!
16. Februar 2018 : Dietrich Nelle: Das Koalitionspapier ist ein großer Wurf!
15. Februar 2018 : Automatisierte Bekämpfung von Opinion Spam
13. Februar 2018 : Der Information Professional als Unternehmensberater
12. Februar 2018 : Digitalisierung – abspringen oder aufspringen?
9. Februar 2018 : Information und die Wissenschaft: Leben im termoniologischen Babylon
8. Februar 2018 : TIB: Vor einer Revolution des wissenschaftlichen Arbeitens
6. Februar 2018 : Ausblick 2018: Siegeszug von Citizen Science
5. Februar 2018 : Just Keep Uploading!
2. Februar 2018 : Informationsversorgung im Angesicht der Frankfurter Skyline
31. Januar 2018 : Die letzte Königin der Fachinformation geht in Rente
30. Januar 2018 : LII: Platform Overload und jedem seine eigene Suchmaschine
29. Januar 2018 : Wir wollen, dass Sie sich an jedem Montag freuen!
26. Januar 2018 : ASIS&T Annual Meeting: Düsseldorfer und deutsche Referenten erfolgreich
24. Januar 2018 : Warum wir uns vor der Künstlichen Intelligenz nicht fürchten sollten
23. Januar 2018 : Wie Sie Ihr Expertentum unter Beweis stellen: Kuratieren, Storytelling, Branding
22. Januar 2018 : InfoPros in der Krise: Was ist eigentlich seit 2015 passiert?
19. Januar 2018 : DIMDI: Lösung von Datenproblemen an der Front der Gesundheitspolitik
18. Januar 2018 : 25 Jahre infobroking lutz: „Transforming Information into Knowledge“
16. Januar 2018 : Subito-Perspektiven: Markenpflege, Infrastruktur ausbauen, zuverlässiger Partner
15. Januar 2018 : Wie aus InfoPros Hidden Information Champions werden
12. Januar 2018 : Netzwerkdurchsetzungsgesetz : Wir müssen die Sozialen Medien ganz anders regulieren!
9. Januar 2018 : Das gigantische Veröffentlichungsprogramm des Michael Klems
8. Januar 2018 : 40 Jahre GBI-Genios: Das Jubiläum des Jahres
20. Dezember 2017 : Geschichte subitos: 1994 – 2018
19. Dezember 2017 : 20 Jahre subito: Rückblick und Ausblick
18. Dezember 2017 : Top Voices auf LinkedIn: Reputationsschub für Blogger
15. Dezember 2017 : 2007 und 2017: Das Entschwinden der Branche
14. Dezember 2017 : ZB MED: „Erfolgreicher Start einer Neuausrichtung“
12. Dezember 2017 : Warum hält GESIS Datenbanken nicht vor, obgleich das nichts kostet?
11. Dezember 2017 : GESIS: Recherche nach Foschungsleistungen total kommerzialisiert
8. Dezember 2017 : Blockchain: Disruptiv, aber ganz besondere Chancen
7. Dezember 2017 : Arne Krüger: Mit Zen Buddhismus und Gemeinwohlorientierung zum wirtschaftlichen Erfolg
5. Dezember 2017 : Sabine Graumann geht? Nein, glücklicherweise nicht!
4. Dezember 2017 : Was die „Steilvorlagen“ wirklich bedeuten
30. November 2017 : Internet Librarian: Success Stories Bibliotheken, Content Marketing, multimediales Storytelling
29. November 2017 : LII opens in less than a week
28. November 2017 : Deutsch-polnische Zusammenarbeit kennt keine Grenzen
27. November 2017 : Sozialwissenschaftliche Datenbanken sollen auf 1/6 geschrumpft werden
24. November 2017 : LexisNexis: Compliance, Reputationsrisiko und Reichweite Weltweit Gutes tun und dabei auch verdienen
23. November 2017 : Digina-Konferenz: Mehr Regulierung, mehr Standards und vor allem mehr Vertrauen
22. November 2017 : Virtual Reality: Was wird diese Technologie leisten?
20. November 2017 : Michael Klems Fünf-Stufen-Plan für Markenkollisionen
17. November 2017 : 10 Jahre später: Der anspruchsvollste Versuch, die Biodiversität unseres Planeten zu erhalten
16. November 2017 : Songdo City: Zukunfts- oder Geisterstadt?
14. November 2017 : Was können wir von britischen Information Professionals lernen?
13. November 2017 : Digitaler Nachlass: Wie sichere ich mein Business nach dem Tode?
9. November 2017 : LII: Bringing the information community together
7. November 2017 : Disruption: Was machen wir, wenn wir auf Erfahrungen nicht aufbauen können?
6. November 2017 : Können Disruptionen vorausgesehen und gesteuert werden?
3. November 2017 : Verlegerische Qualität als gefährdete Spezies
2. November 2017 : Mit Kunde König auf Augenhöhe verkehren!
27. Oktober 2017 : Disruption: Nicht auf Positionierung des Kaninchens vor der Schlange beschränken
26. Oktober 2017 : Vor 15 Jahren: Das Ende des Pioniergeistes
24. Oktober 2017 : Steilvorlagen/Datenbankfrühstück: Halten Sie Ihren Limbi bei Laune!
23. Oktober 2017 : Steilvorlagen für den Unternehmenserfolg: Die kritischen Punkte
20. Oktober 2017 : Steilvorlagen: Auf jede Kritik an Referenten und Inhalten 5,8 lobende Stimmen
19. Oktober 2017 : Bibliothekare: Was wollen meine Stakeholder, und wie kann ich sie überzeugen?
17. Oktober 2017 : 88% der Steilvorlagen-Teilnehmer: Erwartungen erfüllt oder übertroffen
16. Oktober 2017 : Steilvorlagen: Mission Completed und ein großer Erfolg!
13. Oktober 2017 : How Google should be regulated
11. Oktober 2017 : Wie InfoPros Künstliche Intelligenz anwenden
9. Oktober 2017 : Digital Work – wie macht ihr das eigentlich?
6. Oktober 2017 : Münchner Kreis: Einer „Digitalen Sozialen Marktwirtschaft“ entgegen?
5. Oktober 2017 : Dramatische Situation der Informationszentren – Die Herausforderungen
2. Oktober 2017 : Wie Factiva die semiprofessionellen InfoPros gewinnen will
28. September 2017 : Gegen den Bedeutungsverlust der Information Professionals
26. September 2017 : Information Professionals: Kernaufgaben im Angesicht der Digitalisierung
25. September 2017 : Erfolgreiches Marketing auf YouTube – Arbeiten mit LexOffice und F.A.Z-Datenbank
22. September 2017 : Bredemeier verlässt „Steilvorlagen“ – Praxisrelevanz bleibt unser Mantra
20. September 2017 : 20 Jahre Subito: Eine Einrichtung mit Zukunft
18. September 2017 : Rechercheeffizienz, Hootsuite und Salesforce – Die überlegene Alternative zu Google Translate
15. September 2017 : Neustart b.i.t.verlag: Erfahrungen und Perspektiven
13. September 2017 : Wankt das Google-Monopol?
11. September 2017 : Öffentlichkeit für InfoPros im publizistischen Alleingang
8. September 2017 : Video-Marketing, ein Erfolgsmodell für die InfoPros
7. September 2017 : Infowissenschaft: Regelungskäfig staatlicher Fürsorge verlassen und Freiräume zurückgewinnen
4. September 2017 : Die Herausforderung durch „Disruptoren“
1. September 2017 : Neue Services für den „Grünen Weg“
30. August 2017 : ORCID an der TU Dortmund: Wissenschaftler ihren Publikationen eindeutig zuordnen
28. August 2017 : Informationswirtschaft: Wegfall der Zwischenebenen und existenzielle Überlebensfragen
24. August 2017 : Aufstieg, Niedergang und Ende des DBI: Ein Lehrstück mit aktueller Bedeutung
22. August 2017 : Wirtschaft und Politik: Die Zeit der naiven Kumpaneien ist vorbei
21. August 2017 : Abhängigkeit der Autoren von Verlagen oder der Politik: Was ist besser?
17. August 2017 : Dinges & Frick insolvent, aber Fachverlag besteht weiter
16. August 2017 : Der InfoPro hat das Wort: Dramatische Situation in Informationszentren
15. August 2017 : „Uphill Struggle“ der Informationsanbieter im Marketing
11. August 2017 : Trends und Macher der Branche 1986 – 2016
9. August 2017 : Wie Zeitungsinhalte Forschung und Entwicklung befördern (FAZ-Archiv)
7. August 2017 : 25 Jahre PROJECT CONSULT: Die Informationsbranche zwischen Technik- und Contentorientierung
3. August 2017 : „Steilvorlagen“: das finale Programm
2. August 2017 : „Social Live“-Streaming Services: Wer sie warum nutzt und sendet
31. Juli 2017 : Strukturwandel der PATINFO und was dafür spricht
28. Juli 2017 : Kurt Venkers Utopie: So wünschenswert und doch so weit entfernt
26. Juli 2017 : Digitalagentur: Standardisierte Offenlegungspflichten für Algorithmen
25. Juli 2017 : Falsche Zitierpraxis und schwieriges Selbstverständnis unserer Community
24. Juli 2017 : Utopische Entwürfe zur Zukunft der IuD
21. Juli 2017 : Heiko Maas und die Digital-Agentur: Was denkt sich der Minister?
19. Juli 2017 : Fragmentierung zwischen wissenschaftlichen und öffentlichen Bibliotheken überwinden!
17. Juli 2017 : Digitale Disruption als Chance für InfoPros
14. Juli 2017 : Den Dokumentaren fehlt eine angemessene Vertretung
11. Juli 2017 : Kontrovers diskutiert: Warum das Deutsche Bibliotheksinstitut unterging
8. Juli 2017 : Das neue Urheberrecht ist durch: Die Bewertung
7. Juli 2017 : Money20/20: FinTechs und Banken treiben Digitalisierung der Finanzwirtschaft voran
5. Juli 2017 : SVP-Fachtagung: Vom bewussten Gleichgewicht mit digitalen Helfern
3. Juli 2017 : UrhWissG: Freude und Entsetzen nach Abstimmung im Bundestag
30. Juni 2017 : Patenttrolle erfolgreich mit Defensivpublikationen bekämpft
28. Juni 2017 : Fact Checking gegen Fake News: Wie wir gewinnen
26. Juni 2017 : Zukunft der Informationswissenschaft: Vom Information Retrieval zur Wissensorganisation
23. Juni 2017 : Fake News in etablierten Medien, Aktualitätswahn und Skandalisierung
21. Juni 2017 : Welche Zukunft hat die Informationswissenschaft?
19. Juni 2017 : LII: Das bislang ehrgeizigste Programm trifft den Nerv der Branche
16. Juni 2017 : PATINFO verteidigt locker Monopolposition bei Patentinformationen
14. Juni 2017 : Die DGI kann nicht neu erfunden werden
12. Juni 2017 : Rückzug der DGI auf geschlossene Wagenburg klassischer Dokumentationsthemen
9. Juni 2017 : „Palastrevolte“ setzt neuen DGI-Vorstand mit geringer Zukunftsorientierung ein
8. Juni 2017 : Chapeau für ein offenes Wort zu Standardpraktiken der Verleger!
6. Juni 2017 : Die ursurpatorische Praxis der Verleger gegen ihre Autoren
1. Juni 2017 : Metager ermöglicht Suche in der Suche
30. Mai 2017 : Zukunft der Informationswissenschaft/Informationswissenschaft und Digitalisierung
29. Mai 2017 : Fake News und Qualitätsmedien, gar nicht so verschieden
26. Mai 2017 : Patent Landscape Analysis in sechs Schritten
23. Mai 2017 : State of the Art bei Wissenschaftlicher Software
19. Mai 2017 : Zur Käfighaltung des Menschen
17. Mai 2017 : Datenmanagement ohne Professionals, Infrastruktur und Tools
15. Mai 2017 : Vor Zerstörung des Archivgeschäfts der Zeitungsverlage?
11. Mai 2017 : Anforderungen an Information Professionals: Der „Minimal Set“
10. Mai 2017 : Marketing Intelligence Professionals: Die aktuelle Lage
8. Mai 2017 : Die wissenschaftliche Bbliothek als 4. Ort: Scouting, Recommending, Implementing
5. Mai 2017 : Die wissenschaftliche Bibliothek als vierter Ort
3. Mai 2017 : Der Untergang des DBI, ein Lehrstück für heute
2. Mai 2017 : „Next Generation Search Systems“: Finden, Empfehlen, Antworten
28. April 2017 : Fake News, Cyber War und Friedensforschung
26. April 2017 : 5 Wege zur Verbesserung Ihrer PR-Stärken
24. April 2017 : Was für eine Zukunft für die Informationswissenschaft?
21. April 2017 : Potenziale der Digitalisierung und Handlungsbedarf
19. April 2017 : Mehr Querdenker in Qualifizierung, Wirtschaft und Politik!
18. April 2017 : Wie wir die Offene Gesellschaft in Osteuropas Bibliotheken brachten
12. April 2017 : Central European University – Wird der Siegeszug der Offenen Gesellschaften auch in den Bibliotheken zunichte gemacht?
11. April 2017 : Digitale Information und Manipulation: State of Discussion
10. April 2017 : 500.000 Daten-Stewards für den Umgang mit Forschungsdaten
6. April 2017 : Anbieterinformationen: Understanding Information Spaces
5. April 2017 : Wie man auch ohne offiziellen Zugang zu Elsevier über die Runden kommt
3. April 2017 : Textroboter Milli auf dem Weg zur weltweiten Anerkennung
31. März 2017 : Geständnis zum 1. April – Open Password entsteht durch Textroboter
29. März 2017 : Digitalisierung: Warum die Besetzung von Buzzwords sinnvoll ist
27. März 2017 : Müssen wir die letzten InfoPros unter Artenschutz stellen?
23. März 2017 : LII 2017: New rules in the post Brexit, post Trump world
22. März 2017 : Schnittstelle Dokumentation – Ausstellung, Restaurierung, Digitalisierungs- und Publikationsprojekte
20. März 2017 : Was das UrWissG wirklich bedeutet
17. März 2017 : Sicherung der Unternehmensreputation in einer postfaktischen Welt
15. März 2017 : Vera Münch Information Professional des Jahres
13. März 2017 : vfm: Big Archive medial entgrenzt – sozial vernetzt
10. März 2017 : MetaGer boomt – MetaGer rockt
8. März 2017 : KIBA: Pro Diskurs, Vernetzung, Förderung
6. März 2017 : Zur Urheberrechtsdebatte: Mythen und reale Problemlagen
2. März 2017 : Social Media für Jobsuche immer wichtiger
1. März 2017 : Eugene Garfield 1925 – 2017
24. Februar 2017 : Referentenentwurf zur Reform des Urheberrechts ist positiv zu bewerten
21. Februar 2017 : Digitalisierung soll zentrale Herausforderung der nächsten Jahre werden
20. Februar 2017 : InfoPros, hört auf Euer Bauchgefühl!
17. Februar 2017 : Brokern mit weniger als zehn Vermittlern vor dem Aus
15. Februar 2017 : InfoPro des Jahres: Rudolf Mumenthaler
13. Februar 2017 : Wenn InfoPros gefeuert werden, werden sie halt Lektor
9. Februar 2017 : ODOK: Hochrelevante Vorträge, kompetente Referenten – und dennoch in Existenznöten
8. Februar 2017 : Zur wirtschaftlichen Attraktivität von Open Access
7. Februar 2017 : Ein Marathonstaffellauf für die Wiedergeburt der ZB MED
3. Februar 2017 : USA im Zeichen von Trump: We must now demonstrate our values
2. Februar 2017 : Bundesregierung: Mehr Internationalisierung für Bildung, Wissenschaft und Innovation!
31. Januar 2017 : Wird Düsseldorf eine smarte Stadt?
30. Januar 2017 : Neue Kompetenzen für den InfoPro 2017
27. Januar 2017 : Noch nie war die Wissenschaft so sehr gefährdet.
26. Januar 2017 : APE-Teilnehmer zur Vertrauenskrise der Wissenschaft
25. Januar 2017 : Die Mission der Bibliotheken ist die Verbesserung der Gesellschaft
22. Januar 2017 : Ein neuer Ansatz für die Dabatte zur „Zukunft der Bibliotheken“
20. Januar 2017 : Corporate Social Responsibility: Das Zeitalter charakterloser Konzerne geht zu Ende
18. Januar 2017 : Multisprachliche Expertennetzwerke zur Bekämpfung der Cyberkriminalität
16. Januar 2017 : Die zehn wichtigsten Trends in der Informationsbranche
15. Januar 2017 : Informationen ohne Evaluierung? – Vertrauenskrise zwischen Eliten und Bürgern
13. Januar 2017 : Ein Deal mit Elsevier verheißt nichts Gutes
12. Januar 2017 : „Scheinwerfer auf die Leidenschaft für Information“
10. Januar 2017 : Informationswissenschaft ohne Zukunft?
8. Januar 2017 : 2016/2017: Das Internet wird zum Netz des Hasses
22. Dezember 2016 : Es wird Weihnachten – was wünschen sich Information Professionals?
21. Dezember 2016 : Die Wiedergeburt der Content-Branche
18. Dezember 2016 : Die Fachhochschulen werden ihrem Bildungsauftrag untreu
16. Dezember 2016 : LII 2016: „An amazing time to work as InfoPro“
14. Dezember 2016 : LII 2016: Die bestmöglichen ROI für InfoPros
12. Dezember 2016 : Die Informationsbranche muss dem „Postfaktischen“ widerstehen.
9. Dezember 2016 : Fachhochschulen bald nur noch „Universität light“
7. Dezember 2016 : Warum die InfoPros unverzichtbar für ihre Einrichtungen sind
4. Dezember 2016 : Wem gehört die Zukunft der Chemieinformation?
2. Dezember 2016 : Die InfoPros desorientieren das Volk
30. November 2016 : „Nicht die InfoPros auf die Couch, sondern die anderen!“
29. November 2016 : Der Information Professional als Superman
28. November 2016 : Thomson Reuters, Asien und der russische Markt
25. November 2016 : Wie Elsevier bei einer Zeitschrift besiegt wurde
23. November 2016 : Die Ethik der Verleger
21. November 2016 : Müssen Wettbewerbsbeobachter Großmeister werden?
17. November 2016 : So läuft die Digitalisierungsoffensive der Regierung ins Leere
16. November 2016 : Der Open-Access-Value-Chain
14. November 2016 : US-Wahlen und Informationsbranche: Gegen Trump hilft nur der liebe Gott
10. November 2016 : Private Equity: Milliardengewinne oder unter Brücken schlafen
8. November 2016 : Der US-Wahlkampf und die Informationsbranche
7. November 2016 : Überleben der InfoPros in der Attention Economy
3. November 2016 : Niedrigere Nutzung im Realtime-Bereich kostet Arbeitsplätze
2. November 2016 : Neuer Standard gegen Bestechung und Korruption
30. Oktober 2016 : InfoPro-Beruf mit Zukunft, wenn Ausbildung reformiert wird
27. Oktober 2016 : Das Entstehen einer Steilvorlagen Community – Ergebnisse der Veranstaltungs-Umfrage
25. Oktober 2016 : Deutsche Bank schließt Leuchtturm DB Research
24. Oktober 2016 : Wie Künstliche Intelligenz unser Leben revolutioniert
20. Oktober 2016 : Steilvorlagen: Warum die Informationsbranche sich regelmässig treffen muss in Bildern
18. Oktober 2016 : Den Information Professional für morgen qualifizieren
17. Oktober 2016 : InfoPros im politischen Prozess: Kann das funktionieren?
14. Oktober 2016 : Smartphone meistgenutztes Gerät für Internet-Zugang
11. Oktober 2016 : Digitalisierung: Die altruistische Stammesgesellschaft kehrt zurück
10. Oktober 2016 : Warum sich jeder Informationsspezialist „Snowden“ ansehen muss
7. Oktober 2016 : Österreichs Top-Veranstaltung ODOK in Existenznöten
5. Oktober 2016 : Lizenzverträge zwischen Hosts und InfoPros gesetzlich regeln!
3. Oktober 2016 : Textanalyse: Eine der drei wichtigsten Veranstaltungen auf der Buchmesse
30. September 2016 : Online Information Reborn
28. September 2016 : Treffen Sie Open Password auf der Buchmesse – „Steilvorlagen Veranstaltung“
27. September 2016 : Dramatische Situation für die letzten Mitarbeiter von FIZ Chemie
25. September 2016 : „Steilvorlagen“ mit boomender Teilnehmerzahl
23. September 2016 : TIB: Der Direktor geht von Bord
20. September 2016 : Bibliotheken & Archive: Richtig mit Big Data umgehen!
19. September 2016 : Leibniz Gemeinschaft stellt Nebelwerfer an
16. September 2016 : ZB MED im Transformationsprozess mit neuer Leitung
14. September 2016 : Information Professionals – Wandel vom Skeptiker zum Entdecker
11. September 2016 : Ein alternatives Qualifizierungsprogramm für InfoPros
8. September 2016 : Schweizer BIS macht sich fit für politischen Aufstand
6. September 2016 : USA, EU, CH: Wer hat die beste Informationspolitik?
4. September 2016 : Worldbox, Emerging Disruptor für Firmeninformationen
2. September 2016 : Mehr als „Common Search“-Praktiken für Ingenieure
31. August 2016 : Repositionierungen der InfoPros: SVP und infobroker.de
27. August 2016 : Virtual Reality: Wir werden nie mehr das sein, was wir einmal waren
26. August 2016 : Die Schweiz vor digitaler Aufrüstung
23. August 2016 : Be truthful, not neutral!
21. August 2016 : Success Story „Qualifizierung von InfoPros“
19. August 2016 : NRW vor Entprofessionalisierung der wissenschaftlichen Infrastruktur?
17. August 2016 : IVS-Aufgaben und -Services, gibt es Wichtigeres?
15. August 2016 : Statt InfoPros zu helfen, ein hilfloses Kauderwelsch
12. August 2016 : Vom Junk Food der Sozialen Medien in die Informiertheit – wie?
10. August 2016 : Perlen in der Anbieterkommunikation – warum nicht gefunden?
8. August 2016 : Zur Aufgabe des Wahrheitsanspruches in der Wissenschaft
3. August 2016 : Berufsbezeichnung InfoPro: Überholt, nichtssagend, negativ besetzt
2. August 2016 : Verbände und Interessenvetretungen: Stärker vernetzen!
30. Juli 2016 : Profilierungen der Informationswissenschaft in der Lehre
28. Juli 2016 : Deep Web: Stärken, Schwächen, Chancen, Risiken
27. Juli 2016 : InfoPros: From Information to Insight
25. Juli 2016 : Qualifikationsbedarf InfoPros: Yes. We can.
20. Juli 2016 : Studenten verbessern Anbieterstrategien
19. Juli 2016 : Fit für Big Data durch Bitkom-Leitlinen
18. Juli 2016 : CI als viel versprechender Geschäftsbereich für InfoPros
14. Juli 2016 : Nach Megadeal Sorgen um Preise und Servicequalitäten
13. Juli 2016 : Thomson Reuters verkauft Science-Bereich an Private Equity
12. Juli 2016 : Auch Lehre an Fachhochschulen in Gefahr
10. Juli 2016 : Der Hunger von Private Equity nach gesicherten Informationen und Analysen
8. Juli 2016 : Stoppen die iSchools den Niedergang der Informationswissenschaft?
6. Juli 2016 : Wie InfoPros zu „Großmeistern“ werden
4. Juli 2016 : Finalisierung des Programms für „Steilvorlagen“-Veranstaltung
1. Juli 2016 : Brexit fordert Informationsbranche und InfoPros heraus
29. Juni 2016 : Was wir von Festschriften und Herausgebern erwarten
27. Juni 2016 : ZB-MED – Der Schlüssel zum Erfolg liegt in NRW
24. Juni 2016 : Der BREXIT und die Auswirkungen auf die Informationsbranche
21. Juni 2016 : Wie die Informationswissenschaft wieder zu beleben ist
19. Juni 2016 : Wie Minesoft den Wettbewerb gegen große Patentinformationsanbieter besteht
16. Juni 2016 : Bildungsbericht 2016: Die Bildungsrevolution schreitet voran
15. Juni 2016 : Wissenschaftliche Gesellschaften: Zurück in die Steinzeitstandardisierung!
13. Juni 2016 : Die Anti-Fachinformationspolitik der Leibniz Gemeinschaft stoppen!
12. Juni 2016 : Das letzte Einhorn als Bild für die InfoPros
9. Juni 2016 : Altmetrics auf dem Weg zur Standardisierung
8. Juni 2016 : „Steilvorlagen“-Programm für Information Professionals steht
6. Juni 2016 : Gibt es den fachlichen und institutionellen Niedergang der Informationswissenschaft nicht?
3. Juni 2016 : Das 15. ISI in Berlin und in englischer Sprache
2. Juni 2016 : ZB MED wahrscheinlich vor Weiterförderung
1. Juni 2016 : Information Professionals zwischen Stärken und Untergang
30. Mai 2016 : Die Fachinformationspolitik erreicht den Bundestag
27. Mai 2016 : Eine Revolution der InfoPros die ausfallen wird
24. Mai 2016 : Directory of Open Access Journals entfernt 3.300 Zeitschriften
22. Mai 2016 : European Open Science Cloud: Evolution oder Revolution?
19. Mai 2016 : Der Erfinder und Pionier der Datenbankbranche meldet sich zurück.
18. Mai 2016 : Wie die Leibniz Gemeinschaft ihren Gutachtern bei ZB MED nicht gefolgt ist
17. Mai 2016 : Wie die Informationsbranche in das Crowd Blogging einsteigt
13. Mai 2016 : Warum regiert in der Informationsbranche nicht die Weisheit der Vielen?
12. Mai 2016 : „Information Workers of the World, Unite!“
9. Mai 2016 : Praxisorientierte Studenten im ReQuest-Wettbewerb
6. Mai 2016 : Open Password intensiviert „Blick nach Osten“
4. Mai 2016 : InfoPro´s – Mittel gegen eine Bankrott-Erklärung und Bedeutungslosigkeit
3. Mai 2016 : Norbert Henrichs gestorben
2. Mai 2016 : Save the Date für „Steilvorlagen“!
29. April 2016 : Ethisches Handeln im Wettbewerb – ein Nachteil?
27. April 2016 : Eine Nestbeschmutzung der Informationswissenschaft
25. April 2016 : Ein Verband schweigt. Warum?
22. April 2016 : Prince ist tot – Big Data IK Symposium Teil 2 – die 16. Woche im Blick
21. April 2016 : Mögliche Folgen einer ZB-MED Abwicklung – Statement eines InfoPros
19. April 2016 : Leibniz Gemeinschaft hat eine Strategie und NRW hat keine
18. April 2016 : Big Data: Die Ersetzung der Unternehmer und Wissenschaftler durch Algorithmen?
15. April 2016 : Für eine Informationswissenschaft, die der Praxis was bringt
13. April 2016 : Die Abwcklung der Düsseldorfer Informationswissenschaft hat begonnen.
12. April 2016 : Umstätter: Eine neue Informationswissenschaft aus den Ruinen!
8. April 2016 : Gescheiterter Protest – 5 vor dem Komma – Wochenrückblick
7. April 2016 : Unternehmensbibliotheken zwischen Neupositionierung und Überlebenskampf
6. April 2016 : Welcher Interessensverbund vertritt die Information Professionals?
4. April 2016 : #saveiws – Die Chancenlosigkeit der Studentenschaft in Düsseldorf
4. April 2016 : Oh wie schön leakt Panama – das Schein und Sein der Prominenz
2. April 2016 : Das „Aus“ in Düsseldorf ist beschlossene Sache
31. März 2016 : Was wir mit der Mobilisierung pro ZB MED erreichen sollten
30. März 2016 : Wie sich die Informationswissenschaft selbst kannibalisiert
29. März 2016 : Was uns der Bibliothekskongress wirklich brachte
24. März 2016 : Schlechte Prognose für Düsseldorfer Informationswissenschaft
23. März 2016 : Kuhlen: Ein Programm zur Rettung der Informationswissenschaft
22. März 2016 : Informationsbranche erhebt Stimme gegen Abwicklung der ZB MED
21. März 2016 : Ausschließlich negatives Echo auf Abwicklungsbeschluss für ZB MED
18. März 2016 : Breaking News – ZB MED wird abgewickelt
18. März 2016 : Funkstille in Düsseldorf – InfoPros mit Schlapphut – Tweets der Woche
16. März 2016 : Für die Rettung oraler Kulturen in Westafrika
16. März 2016 : Informationswissenschaftler Jürgen Krause gestorben
14. März 2016 : Die Open-Access-Plattform für alle Wissenschaften
11. März 2016 : Offener Web-Index: Ohne Polit-Support
9. März 2016 : „Nur nicht erhobene Daten sind sicher“
8. März 2016 : Die Ausbeutung von Open-Access-Modellen
6. März 2016 : Rainer Hammwöhner gestorben
4. März 2016 : Hamburger Suchmaschinenkongress bepreist Snowden
2. März 2016 : Das Irren der Zeitungsverlage durch die digitale Nacht
29. Februar 2016 : Bibliothekarischer Diskurs muss „angelsächsischer“ werden
26. Februar 2016 : „Deutsche Suchmaschinen in existenzieller Gefahr“
24. Februar 2016 : InfoScience: Strategien gegen den institutionellen Niedergang
22. Februar 2016 : InfoPros: Strategien gegen Bedeutungsverlust – Von Michael Krake
19. Februar 2016 : „Es geht nur um den Sieg, koste es, was es wolle“ (Umstätter zur Verlagslobby)
17. Februar 2016 : Kann Mobilisierung an Uni erfolgreich sein? Ja sicher.
16. Februar 2016 : Gibt es nichts Wichtigeres als Rafael Ball? Doch.
12. Februar 2016 : PUSHDIENST – Wir brauchen keine Bibliotheken mehr – Ist der Furor über Ball berechtigt?
11. Februar 2016 : PUSHDIENST – Nach dem Düsseldorfer Abwicklungsbeschluss: Ist die deutsche Informationswissenschaft noch wettbewerbsfähig?
9. Februar 2016 : PUSHDIENST News
8. Februar 2016 : PUSHDIENST News
5. Februar 2016 : PUSHDIENST News
Anzeige

FAQ + Hilfe
Sie können über die Kopfzeile die einzelnen Jahre per Klick ansteuern. Hierzu einfach auf die passende Jahreszahl klicken (siehe Pfeile)

Nach dem Klick auf die jeweilige Jahreszahl gelangen sie auf die Titelliste des jeweiligen Jahres. Hier dann auf den gewünschten Titel klicken. (Siehe Pfeile)

Wir sind bemüht die Beiträge schnellstmöglich in das Archiv zu übernehmen. Falls ein Beitrag per Klick nicht erreichbar ist zählen wir diese Klicks aus. Sie können aber auf der jeweiligen Seite die beschleunigte Einbindung auswählen.
Die Beiträge von Open Password von 2016 bis 2022 sind seit dem 18.11 2023 über ChatGPT recherchierbar.
Was bedeutet dies konkret? Wir haben alle Beiträge als Wissensbasis über Chat GPT auswertbar gemacht. Wenn Sie ein ChatGPT Plus Nutzer sind und Zugriff auf ChatGPT 4.0 haben, so steht Ihnen das Open Password Archiv dort zur Verfügung.
Mit der Auswertung per KI Abfrage stehen ihnen unendliche Möglichkeiten zur Verfügung. Sie können Themen suchen, Fachbegriffe zusammenfassen und erläutern lassen. Hier geht es zum GPT des Open Password Archiv.
Wir haben alle Pushdienste (Beiträge) der letzten Jahre als PDF vorliegen. Hier sind entsprechende Abbildungen und Bilder enthalten. Die PDFs zu den Pushdiensten werden ebenfalls Schritt für als Link mit in die Beiträge angelegt.
Wir sind bemüht Beiträge nach denen einen hohe Nachfrage besteht in der Anlage vorzuziehen. Hierfür werten wir die Zugriffe auf die Titellisten und die Klicks auf Beiträge regelmässig aus.
Beitrage die als Material benötigt werden, aber noch nicht im Archiv eingebunden sind können wie folgt angefordert werden.
1. Klicken sie auf den Beitrag aus der Titelliste
2. Füllen sie das Formular aus und fragen sie eine bevorzugte Einbindung an
Wir ziehen die Einbindung vor und senden eine Benachrichtigung sobald der Beitrag eingebunden wurde.